
1°/ Objectifs
Ce sujet a pour objectif de mettre en place une application complexe faisant intervenir des connaissances de la plupart des matières techniques enseignées en 3ème année, mais aussi celles des années précédentes. Comme le choix a été fait de "mixer" la SAÉ a S5 vec celle de S6, le cadre de développement de ce sujet relativement fixé et se base sur des codes déjà écrits qu'il faut adapter aux besoins applicatifs. Ces derniers sont en revanches laissés libres.
2°/ Cadre général
La SAÉ consiste a "inventer" une application basée sur des micro-contrôleurs et des objets connectés (téléphones portables, camera ip, ...) pour collecter des données, et ensuite analyser ces données via des méthodes statistiques et de l'IA. Ces données sont soit directement textuelles/numériques, comme c'est souvent le cas avec celles que collectent des micro-contrôleurs grâce à des capteurs, soit au format audio, image, ... qu'il faut traiter pour en tirer de l'information textuelle/numérique. Qu'il y ait ou non traitement, le résultat est stocké dans une base de données non relationnelle, type mongodb. Une application web front-end faite en vuejs permet de récupérer des données dans cette BdD au travers d'une API et de les visualiser. L'API peut également appeler des scripts python qui vont lancer des traitements d'IA sur les données stockées en BdD, les résultats de ces traitements étant eux-même stockés en BdD.
Cependant, votre application doit suivre 2 contraintes majeures :
- elle doit suivre l'architecture logicielle donnée en figure 1 de la section 3. Vous pouvez ajouter des "parties" à cette architecture, mais pas en retirer, quand bien même cela semble bien complexe pour ce type d'application.
- elle doit réutiliser le code déjà écrit dans le cadre d'un prototype d'application (cf . section 4). A noter que ce code ne couvre pas l'entièreté des fonctionnalités prévues pour le prototype (NB : le reste a été perdu par un stagiaire qui ne voulait pas utiliser git :-) ). Il sert juste de cadre de développement mais aussi d'exemple pour certaines fonctionnalités qui ne sont pas abordées en cours.
ATTENTION ! Réutiliser ne veut pas forcément dire faire du copier/coller aveugle de code. C'est plutôt la structuration du code et tout ce qui correspond parfaitement qui doit être conservé. Par exemple, la partie BdD du prototype définit certains schémas de document, avec la syntaxe de mongoose. Cela implique que :
- votre application DEVRA utiliser une base mongo et des schemas mongoose,
- vous devez conserver les schémas qui sont pertinents pour votre BdD,
- vous avez parfaitement le droit de modifier certains schémas ou en créer de nouveaux pour correspondre à votre application.
L'évaluation tiendra compte de l'aspect réutilisation, et sanctionnera tout morceau de code totalement réécrit, alors qu'il était déjà présent dans le prototype et quasi fonctionnel pour votre application. L'idée est de se mettre dans des conditions de développement dans une entreprise où l'on doit faire évoluer un code existant, tout en restant dans un cadre de développement fortement contraint.
Une partie de la SAÉ sera consacrée à la gestion du code et la mise en production. C'est pourquoi les serveurs implémentés devront être "dockerisés" automatiquement, grâce à des processus d'intégration continue.
3°/ Architecture applicative
3.1°/ Structuration fonctionnelle
Elle est donné en figure 1 ci-dessous
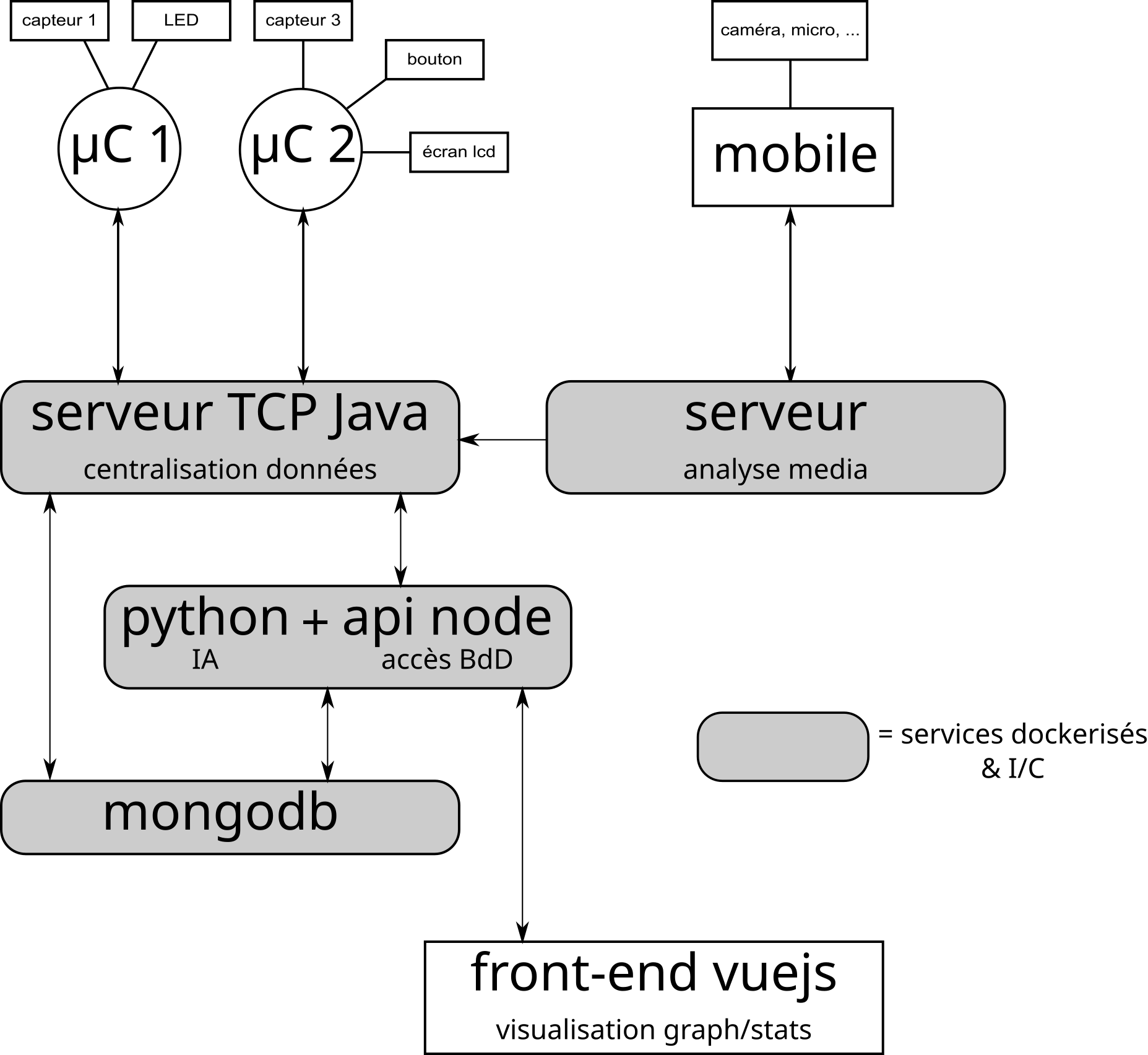 |
| Figure 1 : architecture logicielle imposée |
Description :
- Des modules (au sens large : pression, co2, image, son, ... mais également interrupteur, bouton, led, afficheur, ...) sont connectés à un ou plusieurs micro-contrôleurs.
- Les micro-contrôleurs récoltent des données grâce aux modules de type capteur, interrupteur, .... Les données collectées sont envoyées à un serveur Java dit de "centralisation des données", grâce à des requêtes.
- Les µC sont de stricts clients du serveur. Si ce dernier doit leur envoyer des données (par ex, pour configurer dynamiquement l'intervalle de temps entre 2 mesures de capteur, ou bien pour afficher quelque chose), cela DOIT se faire à la demande des µC, via des requêtes au serveur. Il faut donc écrire le protocole de communication en fonction de cette contrainte.
- Des médias (photos, vidéo, sons, ...) sont capturés grâce à une application exécutée sur un objet connecté mobile (typiquement téléphone, tablette), qui les envoie à un serveur d'analyse multimédia.
- Le serveur analyse chaque média afin de calculer différentes informations, qui sont envoyées au serveur de centralisation, afin d'être stockées en BdD.
- Le serveur de centralisation est connecté potentiellement à plusieurs µC simultanément et ces derniers lui envoient des requêtes n'importe quand.
- Pour envoyer/interroger la BdD, le serveur utilise 2 principes : soit indirectement via une API écrite en node, qui sert également au front-end pour récupérer les données, soit un accès direct via les "drivers" mongodb pour java.
- L'accès direct à la BdD en Java est "expérimental" et considéré comme "non fiable". Toutes les données collectées sont donc par défaut stockées en BdD via l'API, mais il existe également des méthodes dans le serveur qui permettent de stocker certaines données en accès direct. NB : cette situation correspond à une migration de technologie, où l'on développe en utilisant une technologie connue et maîtrisée, mais pour des raisons par exemple de performance, on commence le développement de certaines fonctionnalités avec une autre technologie.
- L'API est de type REST écrite en nodejs,
- Elle est notamment utilisée par le serveur de centralisation des données comme relais vers la BdD, et par le front-end.
- L'API doit proposer des routes pour :
- stocker des données en BdD,
- récupérer des données en BdD,
- lancer des scripts python qui utilise une IA préentrainée pour faire de la prédiction, classification, ...
- Cette API doit pouvoir lancer des scripts python et récupérer le résultat de ces scripts pour ensuite les stocker en BdD,
- Les scripts phyton peuvent interroger la BdD mongo directement afin de récupérer des données, puis utilisent une (ou plus) IA préentrainée pour analyser ces données et renvoyer le résultat à l'API
- Le front-end est une SPA écrite en vuejs.
- Elle est structurée en deux parties : invité et administrateur.
- La partie invité permet simplement d'afficher un tableau de bord, avec des graphiques créés à partir de données stockées en BdD.
- La partie administrateur permet de gérer la "flotte" de µC. Cela peut être un simple catalogue avec ajout/suppression, ou bien permettre de configurer dynamiquement les µCs.
- Les fichiers HTML+JS+CSS de la SPA sont stockés et servis par l'API node
- Tous les serveurs et la SPA sont développés en utilisant des outils de "versioning" permettant d'avoir des branches de développement et de production séparées.
- Leur développement utilise des processus d'intégration continue afin d'intégrer directement les modifications de codes soumises et produire les versions déployables des serveurs.
- Ceux-ci sont déployés sous la forme de conteneurs docker, lancés automatiquement après déploiement.
3.2°/ contraintes & libertés
Vous devez trouver un contexte applicatif qui soit différent de celui du prototype mais qui soit compatible avec la structure exposée ci-dessus.
Les autres contraintes logicielle à respecter sont :
- le serveur qui sert à centraliser des données, doit être écrit en Java, basé sur des sockets TCP et être multi-threadé afin de servir plusieurs µCs concurremment, sachant que :
- il reçoit des données directement via connexion TCP de la part des µCs, éventuellement d'autres objets connectés et du serveur d'analyse de médias,
- il interagit également avec la BdD mongodb de deux façons : la principale est via un API REST écrite en node, la secondaire directement via l'API Java pour mongodb,
- le serveur d'analyse ne doit pas être un serveur web type API REST (cf. ci-dessous), sachant que :
- il reçoit des médias de la part d'au moins 1 objet connecté fonctionnant sous android/iOS équipé d'une caméra, micro, ... (typiquement mobile, tablette).
- il analyse les médias reçus, en tire des informations qu'il envoie au serveur de centralisation,
- la BdD qui centralise les données se base forcément sur mongodb comme sgbd,
- il faut utiliser au minimum une IA préentraînée, appelée via un (ou plusieurs) scripts python inclut sur le même serveur que l'API,
- ces scripts python sont appelés soit "à la main", soit via une requête à l'API. Ils accèdent directement à la base mongo pour récupérer les données utilisées par l'IA.
- le front-end est en en vuejs, avec des graphiques/stats produits dynamiquement à partir de données de la BdD,
- le développement se fait en utilisant des processus d'intégration continue,
- les serveurs sont déployés sous la forme de conteneurs dockers, produits à la fin du processus d'intégration continue, si possible de façon automatique.
- le versioning + intégration continue qui se font via les serveurs gitlab et jenkins du département (NB : ce qui veut dire accès VPN si vous êtes à l'extérieur du réseau fac)
En dehors de ces contraintes, vous êtes libres d'adapter/ajouter des éléments en fonction de votre application, notamment :
- le serveur d'analyse multimédia peut prendre la forme d'un serveur basé sur TCP (comme dans le prototype), écrit en Java/C/C++/node/pyhton/..., ou bien un serveur basé sur des websocket, ou encore un autre protocole, du moment qu'il ne fonctionne pas comme un serveur HTTP de type API REST. Le choix se fait en fonction du type de traitement qu'il doit faire et qui sera plus facile d'écrire dans tel ou tel langage. ATTENTION, ce choix impacte également la partie programmation des objets connectés qui vont lui envoyer des données.
- le serveur d'analyse multimédia peut être mono ou multi-threadé.
- L'objet (ou les) connecté au serveur d'analyse peut être programmé en natif avec android et/ou iOS, ou bien en hybride avec des framework tels que ionic ou quasar. En revanche, choisissez une solution pertinente par rapport au serveur d'analyse. Par exemple, un mobile avec une application hybride ne pourra fonctionner qu'avec un serveur d'analyse basé sur des websockets, alors qu'en natif, TCP fonctionnerait.
- si besoin, le serveur d'analyse peut en plus recevoir des médias de la part d'objets connectés non android/iOS, notamment des µCs ou des cameras IP.
- les graphiques dynamiques et les stats. affichés par le front-end peuvent être créés à l'aide de n'importe quelle bibliothèque JS,
- vous pouvez entraîner vous-même une IA s'il n'existe aucun modèle préentraîné correspondant à vois besoins. Vous pouvez également utiliser plusieurs modèles pour répondre à des problématiques différentes (prédiction, classification, prise de décision, ...)
Du point de vue matériel, les contraintes sont :
- le nombre de µC : au moins 1,
- le nombre et types de modules connectés aux µCs : au moins 2,
- le nombre d'objets android/iOS connectés au serveur d'analyse : au moins 1,
- le nombre d'objets non android/iOS connectés au serveur d'analyse : optionnel
Remarques & conseils :
- Si possible, choisissez un contexte qui soit entièrement cohérent, c'est-à-dire où les données collectées via les µC et les autres objets connectés servent un même but, et où il soit possible de faire de l'IA sur ces données.
- Dans l'idéal, la partie serveur d'analyse doit être réellement implémentable, par exemple grâce à l'utilisation de opencv pour les images. Ne choisissez donc pas des analyses trop complexes, genre reconnaissance vocale. Cependant, cela peut venir en contradiction avec la consigne de cohérence de fonctionnalités mentionnée juste avant. Dans ce cas, privilégiez le fait que la partie analyse soit faisable. Le professeur référent pour cette partie (G. Perrot) pourra vous conseiller..
- Pour les capteurs reliés aux µC, vous devez vous baser sur quelque chose d'existant, sachant qu'un nombre impressionnant de type de capteurs est disponible. Il suffit d'aller sur des sites marchands (genre gotronic, lextronic) pour le constater et trouver ceux qui vous conviennent. Si votre contexte exige du matériel qui n'est pas disponible au département, l'équipe pédagogique verra s'il est possible de le commander et de l'avoir à un prix et délai raisonnable. Sinon, vous devrez simplement écrire du code qui simule le fonctionnement de ce matériel.
Quelques exemples de contexte :
- surveillance de présence dans des bâtiments, des manifestations,
- gestion d'une épreuve sportive (avec dossards pucés rfid et analyse photo finish)
- course d'orientation (boîtiers qui bipent quand on arrive près de l'objectif, et validation grâce à une photo de l'objectif)
- gestion d'un plateau d'emission de variété (boîtiers de type buzzer pour les quizz, enregistrement audio pour mesurer la rires/applaudissements/...)
4°/ Le prototype de départ : surveillance domotique
Dans une maison, des boîtiers permettent de faire des mesures à intervalles réguliers. Ces boîtiers contiennent des micro-contrôleurs de type esp8266, connectés à des capteurs. Par exemple, on cherche à mesurer la température et pression atmosphérique sur la terrasse, la luminosité dans chaque pièce (= lumière allumée ou non), la production électrique de panneaux photovoltaïques, etc. L'objectif de cette collecte de données est de faire par exemple du suivi/gestion de consommation énergétique, au travers de la visualisation de graphiques, statistiques, ... via un navigateur.
Le propriétaire peut également utiliser son téléphone portable et des caméra IPs pour prendre des photos du ciel, qui vont être analysées par un serveur afin d'en tirer des informations chiffrées, par exemple la nébulosité, le % de chance qu'il pleuve, etc.
Enfin, ces informations peuvent être croisées avec celles collectées via les micro-contrôleurs, puis utilisées comme entrée dans une IA pour faire de la prévision météorologique, et prendre des décisions concernant la maison, comme par exemple fermer les volets, éteindre des lumières, ...