
|
NEWS
|
Cet article permet de télécharger les sources des différentes parties du prototype d'application qui sert de base à la SAÉ. Si nécessaire, des explications sur la mise en place de l'environnement de développement sont fournies. Le code étant très peu commenté (comme souvent avec les prototypes), des explications sur les principes d'implémentation sont également fournies dans cet article.
1°/ Mise en place générale
On suppose dans la suite que le répertoire principal de l'application est HomeWeather. Les sous répertoires contiennent chacun une partie de l’application :
- CentralServer : les sources du serveur de centralisation des données
- WeatherAPI : les sources de l'API node
- AnalyzeServer : les sources du serveur d'analyse de données envoyées par un téléphone
- MobileWeather : les sources de l'application mobile android, qui envoie des photos au serveur d'analyse
- WebWeather : les sources du front-end en vuejs
Ces différentes parties nécessitent d'installer au préalable :
- node, en version >=16
- npm, en version >=8
- idea
- un serveur mongodb, en version >=6
- vue-cli, en version >=4.5
D'autres installations sont parfois nécessaires uniquement pour certaines parties. Dans ce cas, elles sont décrites dans les sections ci-dessous.
2°/ Mongodb
La base mongo sert a collecter les données issues de boîtiers à base de µC, appelés "modules", ou bien d'un serveur d'analyse d'images. Chaque module est référencé dans la collection modules, avec un nom, surnom, et clé uniques. Normalement, ces noms sont générés lorsque le module arrive à se connecter pour la première fois au serveur. Dans ce cas, il demande à faire un auto-enregistrement auprès du serveur, et ce dernier va lui générer un nom, surnom et une clé. Le module se contente d'envoyer le type de µC et de circuits électroniques reliés au µC (nommés chipset dans la suite). Les chipsets sont par exemple des senseurs, des switch, .... Ils sont enregistrés dans une collection nommée chipset. A noter que si un de ces chipsets n'existe pas en BdD, ce n'est pas bloquant pour l'application. Dans l'ideal, le front-end devrait permettre d'ajouter à volonté des chipset mais également de modifier les informations d'un module.
Quel que soit l'origine des données (module ou serveur), les données sont enregistrées dans une collection nommée measures. Chaque mesure est typée (par exemple "temperature") et horodatée. Quand le mesure provient d'un module, l'id du module est également renseigné.
Enfin, les gestion des utilisateurs de la partie front-end est assurée via une collection users. Chaque utilisateur est associé à un login, mot de passe, mail, droit d'accès ainsi qu'un id généré lors d'une connexion.
La structure de ces collections est décrite dans les fichiers xxx.schema.js du répertoire models de l'API node. Même si ces schémas sont écrits en utilisant la syntaxe de mongoose, ils sont parfaitement lisibles pour comprendre la structure des collections. Le seul point notable est qu'il n'y a aucun sous-document utilisé. Par exemple, les documents de measures font référence à un module en utilisant l'id d'un document de modules, plutôt que de faire un sous document contenant entièrement l'objet module.
3°/ Serveur de centralisation des données
sources :
3.1°/ configuration IDEA
Avant de récupérer l'archive du projet, il faut configurer IDEA afin d'utiliser les bibliothèques de classes nécessaires à la connexion à une BdD mongo. Comme pour javafx, le plus simple est d'installer ces bibliothèques de façon globale pour IDEA, afin de pouvoir s'en servir pour tous les projets. Dans la procédure ci-dessous, on suppose que ces bibliothèques seront installées dans /usr/local/share/java/mongodb-driver-sync mais cela peut être fait dans n'importe quel répertoire.
Pour ce faire (sous linux) :
- télécharger [ mongo-java.tgz ]
- créer un répertoire /usr/local/share/java/mongodb-driver-sync
- décompacter mongo-java.tgz dans ce répertoire : cela crée 4 fichiers .jar
- lancer idea et ouvrir un projet existant
- aller dans le menu File -> Project Structure
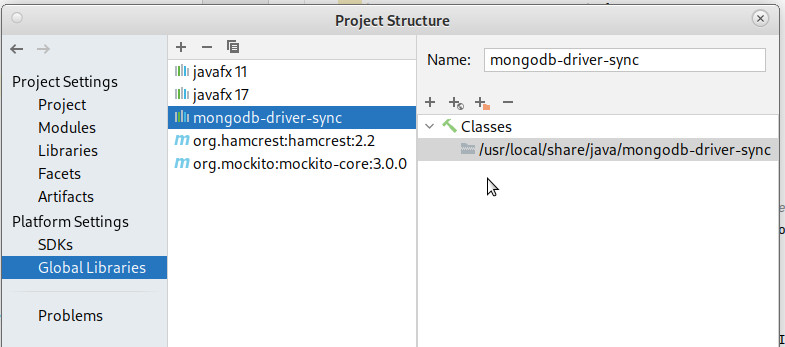
- dans la fenêtre qui s'ouvre, choisir Global Libraries puis cliquer sur le + de la sous-fenêtre centrale (infobulle = New Global Library)
- dans le menu contextuel qui apparaît, choisir Java,
- dans l'explorateur qui apparaît, indiquer le chemin d'accès aux .jar : /usr/local/share/java/mongodb-driver-sync
- cliquer sur "OK". La fenêtre devrait ressembler à celle ci-dessous
3.2°/ Mise en place du projet
Dans un terminal :
# on se trouve dans HomeWeather
tar zxf weather-centralserver_1.0.tgz
cd CentralServerL'archive des sources contient déjà un projet IDEA. Il suffit donc d'ouvrir le projet se trouvant dans CentralServer. C'est un projet avec 2 modules séparés : un pour le serveur, un pour le client de test.
Si vous avez correctement fait l'étape 1.1, il ne devrait pas y avoir d'erreurs de type nom de classe inconnu dans les classes du serveur.
Si c'est le cas, c'est que le module serveur n'est pas configuré correctement, sans doute parce qu'il n'a pas les .jar de mongodb en dépendance. Pour faire cette configuration :
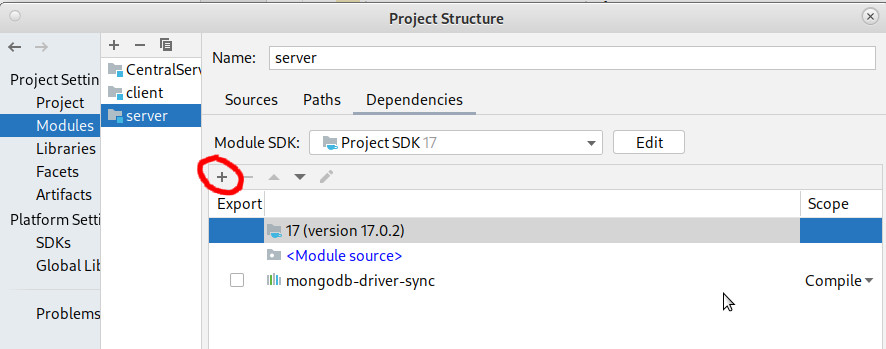
- aller dans le menu File -> Project Structure
- dans la sous-fenêtre de gauche, choisir Modules
- dans la sous-fenêtre centrale, choisir server
- dans la sous-fenêtre de droite, cliquer sur le + et dans le menu contextuel, choisir Library
- dans la fenêtre de dialogue qui apparaît, sélectionner mongodb-driver-sync et cliquer sur Ok
- la fenêtre principale devrait ressembler à celle ci-dessous
3.3°/ Exécution
Le projet contient déjà deux configuration d'exécution, une pour le serveur et une pour le client. Le client sert uniquement à tester les fonctionnalités du serveur sans avoir besoin des µC. Dans l'état actuel du serveur, le client peut envoyer trois types de requêtes :
- pour simuler l'auto-enregistrement d'un module (c.a.d. un boitier d'acquisition à base de µC)
- pour simuler l'envoi de données par un module au serveur, afin de les stocker en BdD
- pour simuler l'envoi de données par un serveur d'analyse, afin de les stocker en BdD
Pour des exemples d'utilisation du client, il suffit de lire le commentaire au début de la classe MainClient
Tests :
- on suppose que l'API node et que le serveur mongodb sont démarrés et que la BdD est dans son état initial (cf. db.init.js dans le projet de l'API node)
- lancer le serveur et ensuite le client. Un terminal s'ouvre dans IDEA pour chacun des deux.
- dans le terminal du client, taper par exemple : 1 esp32 lm35
- la réponse du serveur est un message du type : OK module 3,mod3,2e46990d-3e85-45f8-82c8-f05eec1a4567, qui indique que l'enregistrement s'est bien passé et qui renvoie le nom, le surnom et la clé du module.
- NB : lors de la première connexion d'un module au serveur, il demande à s'auto-enregistrer. Il récupère ainsi son nom, surnom et clé et enregistre ces informations dans une partie de la mémoire persistente du µC
- pour vérifier que la BdD a bien été modifiée, on peut utiliser mongosh :
- lancer mongosh
- taper les commandes :
- use weatherapi
- db.modules.find()
- la liste devrait faire apparaître un objet nommé module 3.
3.4°/ Explications
Le serveur est multithreadé, donc il permet de communiquer avec des clients simultanés. Le serveur n'est qu'un relai pour stocker des données dans la BdD. Mais comme ce stockage se fait soit directement, soit via une API, pour chaque requête, il existe une paire de méthodes qui vont effectivement faire la requête en BdD. Pour éviter les conflits entre les threads, ces méthodes sont déclarées synchronized.
Toutes les méthodes d'accès à la BdD sont déclarées dans une interface nommée DataDriver. Cette interface est implémentée dans 2 classes, chacune représentant un moyen d'accéder à la BdD : MongoDataDriver et HttpDataDriver. Leurs principes de fonctionnement est décrit dans les deux section suivantes.
3.4.1°/ Accès direct à mongodb en java
Les bibliothèques installées en 1.1 fournissent toutes les classes nécessaires à la connexion et l'envoi de requêtes, notamment les classes : MongoClient, MongoDatabase, et MongoCollection.
Il existe différentes façon de récupérer des documents dans une collection, mais la plus "versatile" est de créer des POJO (Plain Old Java Object). Un Pojo est simplement une transcription objet des éléments stockés dans une table/collection. C'est un concept qui fonctionne aussi bien en relationnel qu'en non relationnel.
Pour écrire les POJO représentant les documents stockés dans la BdD, il suffit de partir de leur modèle et de la transcrire en une classe avec getter et setter. Chaque champ d'un document correspond à un attribut dans le POJO. Les tableaux sont représentés par des List. A noter qu'il est parfaitement possible de composer des POJO pour représenter un document contenant un sous-document.
Exemple : pour une collection Person, dont la structure est
{
_id: ObjectId,
name: String,
age: Number
}Le POJO équivalent est :
import org.bson.types.*;
class Person {
private ObjectId id;
private String name;
private int age;
public Person() {}
// + getters & setters for all attributes
}
Une fois que les POJO sont écrits, il faut initialiser un "registre des POJOs". Celui-ci sera utilisé pour automatiquement convertir des données venant de la BdD en instance de POJO, et inversement. En fait, on met en place une sorte d'ORM qui évite d'avoir à transformer soi-même du JSON en objet où l'inverse : c'est fait automatiquement :-)
Pour le projet CentralServer, la mise en place du registre se fait dans le constructeur de MongoDataDriver. Ensuite, dans la méthode init(), on initialise une connexion à la BdD, puis on sélectionne la base voulue en spécifiant le registre POJO. Il ne reste plus qu'à mettre en place l'accès aux différentes collections, en spécifiant à chaque fois quel POJO on veut utiliser pour chaque collection.
Exemple tiré des sources :
mongoClient = MongoClients.create(mongoURL);
try {
database = mongoClient.getDatabase("weatherapi").withCodecRegistry(pojoCodecRegistry);
measures = database.getCollection("measures", Measure.class);
...
Après ces instructions, le pseudo-ORM est en place et l'on peut directement récupérer des instances de POJO lorsque l'on fait une requête en BdD, ou bien créer une instance puis la sauvegarder en BdD :
Measure m = measures.find(eq("type","voltage")).first(); // get the first document in measures collection with type = voltage
m = new Measure("voltage", "2023-10-10T10:54:25.238Z", "240", m.getModule());
measures.insertOne(m); // save a new measure document for the same module
3.4.2°/ Accès à l'API via HttpClient
Dans la v11 de Java, l'accès à un serveur http a été réécrit pour être plus polyvalent, au détriment parfois de la facilité d'utiliser les classes fournies. Cependant, on trouve beaucoup d'exemples sur le web, que l'on peut recopier presque tels quels afin de faire des requêtes avec du json comme données.
Le principe général est :
- créer une instance de HttpClient,
- créer une instance de HttpRequest, en utilisant un "builder" de requête,
- envoyer la requête grâce au client http, en spécifiant le format des données de la réponse (par ex, en String). On obtient un objet HttpResponse
Ce qui est résumé dans l'exemple ci-dessous :
HttpClient client = HttpClient.newHttpClient();
HttpRequest request = HttpRequest.newBuilder()
.uri("http://monsite.com")
.header("Content-Type", "application/json")
.method("POST",HttpRequest.BodyPublishers.ofString(payload))
.build();
HttpResponse<String> response = client.send(request, BodyHandlers.ofString())
System.out.println(response.body()); // OK because body is a String
Quand la réponse est elle-même une chaîne de caractère contenant du JSON, il est possible de la transformer en un objet Document, et ainsi accéder facilement aux champs de l'objet. En revanche, quand un champ est lui-même un objet JSON, il faut d'abord récupérer cet objet sous la forme d'un Document et ensuite accéder à ses champs (cf. autoRegisterModule() pour un exemple qui va chercher des champs dans l'objet data)
Ce principe est suffisamment simple pour être "automatiser" sous la forme de méthodes qui vont faire des requêtes de différents type (GET, POST, ...) avec éventuellement des données associées. Le seul problème est la construction de ses données au format JSON qui est un peu fastidieux. En effet, on doit former une chaîne de caractères contenant des " autour de chaque nom de champ et autour des valeurs alphaumériques.
Dans le code source, cette construction est faîte directement avec des \", mais il est possible de construire un objet Document, puis d'utiliser toJson() pour obtenir une chaîne au bon format. Par exemple :
Document doc = new Document();
doc.put("name","toto"); doc.put("INE", "12345N");
Document subdoc = new Document();
subdoc.put("age", 26); subdoc.put("group", "A");
doc.put("infos",subdoc);
System.out.println(doc.toJson());
4°/ API node
sources :
- v1.0 : weather-api_1.0.tgz
4.1°/ Mise en place du projet
Dans un terminal :
# on se trouve dans HomeWeather
tar zxf weather-api_1.0.tgz
cd WeatherAPI
npm installIl suffit ensuite d'ouvrir le projet IDEA se trouvant dans WeatherAPI.
4.2°/ Exécution
Le projet contient une configuration d'exécution pour lancer l'API. Le fichier .env permet de sélectionner le port associé à l'API. Il est fixé à 4567 mais peut être changé, du moment que le même est utilisé ensuite pour le serveur central et le front.
Au premier lancement de l'API, la BdD est créée dans mongodb est quelques documents y sont créés.
4.3°/ Explications
L'implémentation de l'API suit globalement les principes déjà abordés en cours, avec en plus un système de gestion des erreurs multi-langues et facilité par la définition de gestionnaires d'erreur pour chaque "domaine" (cf. fichiers dans commons). Le seul point à mentionner est l'utilisation d'un format unique de réponse de l'API, déjà utilisé lors des cours, à savoir un objet JSON du type : { error : num_erreur, status : http_status, data: réponse }.
Si num_erreur > 0, alors la requête a provoqué une erreur et le message d'erreur est stocké dans data. Sinon, les données issues du traitement de la requête sont dans data.
Comme cette API va servir aussi bien pour stocker des données que pour les récupérer avant visualisation par le front-end, des routes sont déjà prévues pour gérer les utilisateurs et leur authentification. Cependant, celle-ci reste très primaire, puisqu'elle se base sur un simple id lié à l'utilisateur, qui doit être envoyé à chaque requête. De plus, rien n'est fait pour limiter la validité de cet id. Le processus d'authentification devrait donc être totalement réécrit