- Détails
- Écrit par stéphane Domas
- Catégorie : R4A.10 - Compléments web (vuejs)
- Affichages : 21260
- Les démonstrations de ce TD se basent sur les sources disponibles [ ici ].
- Attention, seul le répertoire src est dans l'archive. Il faut donc créer un projet avec vue-cli et remplacer son répertoire src.
1°/ Un dialogue avec résultat
- Comme vu dans le TD consacré à vuetify, le composant v-dialog permet d'afficher au centre de la page du navigateur une boîte de dialogue. On peut notamment fixer sa largeur et son contenu librement.
- En revanche, cette boîte est forcément reliée au composant père où on l'instancie. Ce n'est donc pas une fenêtre applicative, au sens des dialogues en Java.
- Cela implique que ce qui permet à la boîte de s'afficher/disparaître doit se trouver dans ce composant.
- Il faut notamment une variable booléenne qui permet de spécifier si la dialogue est visible ou non et faire un data-binding dessus.
- On peut ensuite créer un élément cliquable (par ex, un bouton) qui va faire passer cette variable à true afin de montrer le dialogue, et celui-ci contient d'autres boutons permettant de mettre la variable à false et ainsi masquer le dialogue.
- Généralement, ce masquage est fait grâce à une fonction qui va faire un traitement particulier après la fermeture du dialogue, selon le bouton que l'on a cliqué pour fermer.
- Ce principe est simple mais il devient fastidieux à mettre en place lorsqu'un composant peut afficher différents dialogues avec la même structure mais avec différents traitements selon le dialogue ET le bouton cliqué.
- Prenons le cas très courant de dialogues avec un titre, un texte et deux boutons : ok & cancel.
- Supposons un composant qui, selon les interactions de l'utilisateur, va afficher deux types de dialogue avec cette structure mais un titre et texte différent. Qui plus est, le traitement à faire après clic dépend du bouton et du dialogue, soit 4 possibilités de traitement, représentés par 4 fonctions dans methods.
- Il y a globalement 2 solutions basiques :
- créer deux instances différentes du dialogue. Cela implique que chacun des 4 boutons appelle une des 4 fonctions de traitement.
- créer une seule instance customisable par props. Cela implique une méthode qui met à jour ces props en fonction de la version du dialogue à afficher, une variable supplémentaire qui stocke cette version, et enfin deux fonctions, un pour chaque type de bouton (ok + cancel) qui vont appeler une des 4 fonctions de traitement par rapport à la version du dialogue (cf. démo).
- Dans les deux cas, c'est du code à écrire, qui va un peu à l'encontre de la philosophie de réutilisation des composants.
- Si on regarde ce qui se fait dans d'autre langages, on constate qu'il est possible de créer des dialogues "à la volée", qui bloquent l'exécution tant qu'ils sont visibles, et qui renvoient une valeur différente selon le bouton cliqué.
- Cela serait fort pratique d'avoir de tels dialogues en vuejs et c'est effectivement possible.
- La seule différence est que la dialogue reste un sous-composant, qu'il n'est donc pas créé à la volée.
- En revanche, on va pouvoir l'afficher grâce à l'appel d'une fonction, qui va retourner une valeur en fonction du bouton cliqué.
- Pour cela, il faut utiliser les promesses et l'attribut ref permettant de référencer un composant pour manipuler l'objet associé dans le DOM.
- Le principe général est :
- on crée un composant, par ex. nommé ConfirmDialog, dont le template est basé sur v-dialog, avec des props qui permettent de spécifier le titre et le texte.
- le v-dialog utilise une variable locale pour piloter son affichage/masquage.
- ce composant contient des fonctions open(), accept(), cancel().
- open() passe la variable à true pour afficher le v-dialog puis crée une promesse qui n'est résolue qu'en cas d'appel à accept() ou cancel(). Bien entendu, ces 2 méthodes sont appelées lorsque l'on clique sur le bouton Ok ou Cancel.
- la fonction accept() résous la promesse avec comme résultat true, alors que cancel() résous la promesse avec comme résultat false (NB : pas de cas d'erreur). Les 2 masquent le v-dialog. On obtient donc un composant qui s'auto-masque.
- dans un composant père, on crée une instance de ConfirmDialog, avec un attribut ref, par ex. ref="mydialog". Cet attribut est spécifique à vuejs et permet dans la partie script de manipuler l'objet dans le DOM correspondant à un composant ou une balise, Pour cela, il suffit d'utiliser this.$ref.nom_ref.
- quand l'utilisateur fait une action qui doit montrer le dialogue, on appelle une fonction de methods. S'il y a plusieurs interactions montrant le dialogue, on écrit une fonction par type d'interaction.
- chacune de ces fonctions assigne une valeur aux variables qui servent de props au dialogue, puis elle appelle sa fonction open() , et attend son résultat. Par ex, let res = await this.$refs.mydialog.open()
- il suffit de vérifier res pour savoir si l'utilisateur à cliqué sur Ok ou Cancel et faire le traitement adapté.
- Cette solution est beaucoup plus souple à mettre en place et demande moins de code à écrire.
- Elle est particulièrement adaptée aux cas de multi-confirmation.
- On peut même l'améliorer en ajoutant des props et des slots afin de customiser un peu plus le contenu, par exemple avec un nombre variable de boutons, un contenu avec des champs de saisie, boutons radio, etc., des valeurs renvoyées plus complexes, ...
- Renommer App.vue.1 dans App.vue.
- lancer npm run serve puis visualiser le résultat dans le navigateur (par ex. http://localhost:8080)
- Montrer le code de EventDialog.vue. qui encapsule un dialogue avec un fonctionnement classique :
- le dialogue utilise la props show fournie par le composant père comme déclencheur d'affichage et émet un événement closeDialog avec true/false comme valeur quand on doit le fermer.
- il ne se masque pas lui-même mais compte sur le composant père pour capturer cet événement et remettre la props show à false pour masquer le dialogue.
- les autres props permettent de customiser le contenu du dialogue.
- Montrer le code de App.vue et les fonctions xxxx1() qui concernent la gestion du dialogue classique.
- Il n'y a qu'une seule instance de EventDialog, mais deux types d'interaction (case à cocher et bouton) permettant de l'afficher. C'est pourquoi on utilise la variable idInteraction pour stocker ce type.
- Quand on capture l'événement closeDialog, on appelle la fonction getAnswerAndClose(), qui sert de switch. En fonction de idInteraction, elle appelle d'autres fonctions pour faire des traitements paramétrés par la valeur de l'événement (true ou false)
- Montrer le code de PromiseDialog.vue. qui encapsule un dialogue avec un fonctionnement basé sur les promesses. On remarque que cela correspond bien au principe décrit plus haut, notamment le fait que l'affichage du dialogue se fait par programmation et non interaction, et que l'on a pas besoin de gérer de façon externe le masquage du dialogue.
- Dans App.vue, montrer les fonctions xxxx2() qui concernent la gestion du dialogue avec promesse. On remarque qu'une fois les logs console enlevés, il y a moins de code à écrire qu'avec la solution classique.
2°/ traiter et afficher les erreurs
- Dans la plupart des applications, une erreur provoque l'affichage d'un dialogue mentionnant l'erreur plus un bouton pour fermer le dialogue.
- Dans certains cas, une erreur ramène l'utilisateur à un point bien précis de l'application.
- Malheureusement, en vuetify, les dialogues ne sont pas reliés à l'application mais à un composant bien précis.
- Cela veut dire que si une interaction d'un utilisateur dans un composant A provoque une erreur et donc l'apparition d'un dialogue, il faudrait en principe que ce dialogue soit instancié dans le composant A.
- Cependant, grâce à vuex, il est possible de contourner cette difficulté et de n'avoir qu'un seul dialogue affichant les erreurs de toute l'application dans le composant racine App.
- Le principe :
- dans le store, on définit deux variables du state : une pour signifier qu'il y a une erreur, l'autre pour contenir le message d'erreur. Par exemple, isError et errorMsg.
- on définit également deux mutations :
- une permettant de passer isError à true et mettre à jour errorMsg. Par exemple, pushError()
- une permettant de passer isError à false. Par exemple, popError()
- on définit un composant basé sur v-dialog. Ce composant mappe isError et msgError (grâce à mapState). Le dialogue est affiché en fonction de la valeur de isError. Il contient un bouton qui appelle la fonction popError() et donc masquer le dialogue
- on crée dans App une instance de ce composant.
- dans n'importe quel composant générant une erreur, on mappe pushError() et dès qu'il y a une erreur on l'appelle.
- Le fait d'appeler pushError() va automatiquement provoquer l'apparition du dialogue au centre de la fenêtre, quel que soit le composant qui a appelé la fonction.
Remarques :
- il est impératif d'utiliser l'attribut persistent de v-dialog afin que le seul moyen de fermer le dialogue soit de cliquer sur le bouton, et donc d'appeler popError().
- il est possible d'étendre ce principe, par exemple en permettant de mettre en file plusieurs messages d'erreurs, d'associer au message d'erreur une route que l'on suit après avoir cliqué sur le bouton de fermeture du dialogue, etc.
- Renommer App.vue.2 dans App.vue.
- lancer npm run serve puis visualiser le résultat dans le navigateur (par ex. http://localhost:8080)
- Montrer le code du store dans store/errors.js (NB: le store est modulaire). Il correspond au principe décrit ci-dessus.
- Montrer le code de ErrorDialog.vue. On remarque que l'affichage/masquage du dialogue est effectivement piloté par la variable isError du store.
- Montrer le code de App.vue. On remarque qu'il y a une seule et unique instance de ErrorDialog.
- Cliquer sur le bouton 'check firstname', ce qui permet de suivre une route pour afficher une premier composant TD3Demo2A, qui mappe la mutation pushError()
- Taper toto dans le champ de saisie : le composant utilise pushError() pour "enregistrer" une erreur dans le store. Cela provoque immédiatement l'apparition du dialogue d'erreur.
- Si on tape autre chose, on suite une autre route pour afficher TD3Demo2B, qui mappe aussi pushError().
- Cliquer sur le bouton sans cocher la case : le composant utilise pushError() et le dialogue d'erreur apparaît de nouveau.
3°/ Eviter l'accès à des composants avec un accès privilégié et à des routes non prévues
- Si on utilise vue-router pour "naviguer" dans l'application, il y a certainement ces cas où suivre une route va provoquer l'affichage de composants dont le contenu ne peut être récupéré/visible que si on a les droits suffisants. Si les droits sont insuffisants, il faut que l'application signale une erreur puis redirige vers une route sans problème d'accès.
- En fait, ce fonctionnement peut être optimisé si on interdit directement le fait de suivre une route menant vers de tels composants. Comme ça, on économise leur affichage et le fait qu'ils échouent lors de la récupération de contenu.
- Pour cela, il faut utiliser les "gardes de navigation" de vue-router. Une garde est simplement une fonction dont le paramètre est une fonction définie par le développeur. Cette dernière sera appelée quand on essaye de suivre une route, voire après l'avoir suivie.
- Dans le cas présent, on va utiliser la fonction beforeEach() qui permet de définir la fonction appelée AVANT de suivre n'importe quelle route.
- Cette fonction peut décider de suivre la route ou non, voire de rediriger vers une autre route.
- Pour autoriser/interdire de suivre des routes privilégiées grâce à des gardes, cela nécessite un peu de code JS dans le fichier décrivant les routes et le store.
- Dans le store :
- on ajoute les mutations/actions permettant de s'authentifier et une variable indiquant l'état authentifié ou non, par exemple auth.
- Dans le fichier des routes :
- on utilise le champ meta de chaque route (cf. API de vue-router : https://router.vuejs.org/guide/advanced/meta.html), pour définir une valeur, par exemple levelAuth, décrivant le niveau d'accès nécessaire qu'il faut pour suivre la route (par ex, 0 = libre, 1 = privilégié). Comme meta est un champ relié à la route, les fonctions qui prennent en paramètre une route y accéder.
- on crée une fonction, par exemple checkAccess(), prenant en paramètre une route. Elle utilise le contenu du champ meta ET le store pour décider si l'accès à la route est autorisé ou non. Elle renvoie true ou false en fonction.
- on crée une garde de navigation qui appelle checkAccess() avec la route à suivre en paramètre. Si elle renvoie true, on continue avec cette route, sinon, on redirige vers la route permettant l'authentification.
- Pour interdire l'accès à des routes non prévues, le principe consiste à créer une toute dernière route, qui accepte n'importe quel chemin (grâce à *). On lui donne un nom avec name, afin de l'identifier facilement.
- Ensuite, dans la fonction de garde, on teste si la route à suivre correspond à ce nom. Si c'est le cas, c'est qu'aucun autre route ne correspond, donc qu'il y a erreur de routage. Dans ce cas, on affiche une erreur et on redirige vers l'accueil.
Remarques :
- ce principe peut être étendu à une granularité plus fine des droits d'accès. Il suffit de modifier la valeur de levelAuth et la fonction de vérification pour tenir compte de la diversité des droits.
- on peut mettre plusieurs gardes, qui vont être appelée dans l'ordre dans lequel on les a définies.
- il existe d'autres type de gardes, par exemple celles que l'on définit pour une route en particulier, voire même à l'intérieur des composants. Pour le principe à mettre en place ici, il est cependant plus court d'utiliser une garde globale.
- Renommer App.vue.3 dans App.vue.
- lancer npm run serve puis visualiser le résultat dans le navigateur (par ex. http://localhost:8080)
- Montrer le code de auth.js dans le store. Le login est assuré par l'action login() et non pas une mutation, pour prendre en compte le fait que généralement, l'authentification est faite auprès d'un serveur, donc avec un appel asynchrone.
- Montrer le code de index.js dans le router. Selon le principe donné ci-dessus, un champ access a été ajouté aux routes et une fonction checkAccess() permet de tester s'il est possible d'emprunter la route. Pour cela, il suffit de tester la valeur de auth dans le store. Comme celui-ci est modulaire, il faut utiliser l'objet store.state.auth pour accéder au state du module auth. Cet objet permet ensuite d'accéder à l'unique variable auth.
- Dans cette démo, il existe une route publique permettant d'afficher le composant FreeView, et une route privilégiée affichant PrivateView.
- La dernière route s'appelle error404 et son chemin est *. Elle sera suivie dès lors qu'aucune autre ne fonctionne.
- Pour écrire la garde de navigation, beforeEach() prend simplement en paramètre une fonction fléchée avec 3 paramètres : la route actuelle, la route à suivre, et une fonction permettant de continuer sur la nouvelle route, ou bien faire une redirection.
- On remarque que le code de cette fonction est simple :
- si la route suivie est error404, on redirige vers l'accueil,
- sinon s'il est possible de suivre la route, on la suit,
- sinon, on signale une erreur (cf. démo 2) et on redirige vers le composant de login.
- Montrer le code de TD3Demo3.vuejs . Il contient 2 boutons permettant de suivre soit la route publique, soit la privilégiée et d'afficher le composant associé en tant que fils de TD3Demo3.
- Cliquer sur le bouton "Follow Free Access route" : on affiche directement le composant FreeView.
- Cliquer sur le bouton "Follow Private Access route" : on obtient une erreur.
- Cliquer sur le bouton "Login", puis taper n'importe quoi comme login/mdp. On obtient une erreur. Si on tape toto/azer, le login est réussi.
- Cliquer de nouveau sur le bouton "Follow Private Access route" : on affiche le composant PrivateView.
- Si on se délogue en cliquant sur "Logout", on ne peut plus accéder à PrivateView.
- Taper une URL avec une route invalide, par exemple localhost:8080/toto. On revient à l'accueil avec un message d'erreur. La route par défaut fonctionne donc bien comme prévu.
- Détails
- Écrit par Super Utilisateur
- Catégorie : R4A.10 - Compléments web (vuejs)
- Affichages : 303
1°/ Principes
L'objectif d'électron est de construire un exécutable à partir du code d'une application web de type SPA, par exemple écrite en vuejs. Pour ce faire, electron embarque dans l'exécutable un moteur d'interprétation JS, qui va afficher le résultat dans une fenêtre classique, telle que celle qu'on crée dans une application Java ou Qt.
2°/ Avec vuejs
Pour créer une application electron à partir d'un projet vuejs, la première étape est d'inclure le plugin electron pour vuejs au projet :
vue add electron-builder
Au cours de l'installation, il est demandé quelle version d'electron doit être utilisée. Généralement, on prend la plus récente, sauf raison impérieuse.
Après l'installation, la différence la plus notable est l'apparition d'un fichier background.js dans le répertoire src. Ce fichier contient les instructions permettant notamment de créer la fenêtre principale et de "lancer" la page initiale de l'application.
Pour faire un test en mode développement, il suffit de lancer :
npm run electron:serveUne fenêtre est créée, relativement similaire à celle d'un navigateur, puisque l'on a accès à l'inspecteur, et que l'on peut suivre des URLs externes.
Pour créer l'exécutable, il faut lancer :
npm run electron:buildLe résultat est placé dans le répertoire dist_electron, avec potentiellement plusieurs versions d'exécutables :
- app image,
- conteneur snap,
- répertoire avec le fichiers nécessaires
- ...
Sous linux, il est possible de configurer electron pour qu'il produise des fichiers .deb
3°/ Problèmes classiques
3.1°/ mode de l'historique de vue-router.
Lorsque l'on crée la version de production, il faut que vue-routeur gère l'historique de navigation dans un mode nommé hash. Généralement, le mode par défaut est history.
Pour régler ce problème, il suffit d'éditer le fichier définissant les routes, contenant généralement la création de l'instance de vue-router. Lors de cette instanciation, il suffit de régler le mode en fonction de si on utilise electron ou non :
export default new Router({
mode: process.env.IS_ELECTRON ? 'hash' : 'history',
base: process.env.BASE_URL,
routes
})
3.2°/ certificats SSL invalides
Il est fréquent qu'un site ou une API utilise des certificats ssl auto-signé, qui ne sont donc pas reconnus par les navigateurs. Dans ce cas, un message d'alerte apparaît et l'on peut passer outre en ajoutant une exception pour le site. En revanche, ce mécanisme d'exception n'est pas disponible dans une application electron. Il faut donc le faire par des instructions.
Pour cela, il faut éditer le fichier background.js mentionné plus haut et ajouter dedans :
// SSL certificate error pass-through
app.on('certificate-error', (event, webContents, url, error, certificate, callback) => {
if (url.startsWith("https://localhost:4567/")) {
event.preventDefault()
callback(true)
} else {
callback(false)
}
})
Le test sur l'URL doit bien entendu être modifié pour correspondre à l'adresse du site ou de l'API qui fonctionne avec des certificats auto-signés.
ATTENTION : en production, il convient d'éviter ce genre de "contournement" et utiliser de vrais certificats, reconnus par les navigateurs.
- Détails
- Écrit par Super Utilisateur
- Catégorie : R4A.10 - Compléments web (vuejs)
- Affichages : 2784
Préambule
- Le code de démonstration repose sur des paquets non standards. C'est pourquoi l'archive disponible ci-dessous inclut toute l'arborescence du projet, excepté le répertoire node_modules.
- Pour les plus curieux qui veulent voir comment est conçu le back-end, une section à la fin de cet article vous permet de le télécharger et vous donne les indications pour l'installer et le configurer sur votre propre machine.
- Le code du front-end peut être téléchargé [ ici ].
- Une fois l'archive décompactée, un répertoire authdemo est créé.
- Aller dans ce répertoire, et exécuter : npm install
- Une fois l'installation terminée : npm run serve
- Le serveur de développement est en https, donc il faut utiliser https://localhost:8080 dans le navigateur. Lors du premier accès, cela produit une erreur car le navigateur ne reconnaît pas le certificat du serveur de développement. Il faut donc lui "forcer la main" et accepter le certificat.
Truc utile :
- Pour que le front-end puisse accéder au back-end, il faut lui donner l'URL d'accès.
- En général, lors du développement, on utilise un back-end également de développement, qui n'est pas forcément celui de production.
- Pour faciliter le passage de version de développement vers production, il est possible de créer à la racine du projet front-end 2 fichiers définissant des variables : .env.development et .env.production
- Par exemple, le fichier .env.development de l'archive contient :
VUE_APP_API_ENDPOINT=https://localhost:3334/authapi- La variable VUE_APP_API_ENDPOINT permet de donner l'URL du back-end. On met donc une valeur pour la version de développement et on met une autre URL dans le fichier .env.production pour la version de production.
- En effet, si on lance un serveur de dev. pour le front-end (avec npm run serve), c'est le contenu de .env.development qui est utilisé. Et si on lance la création de la version de production (avec npm run build), c'est le contenu de .env.production qui est utilisé.
- Ces variables peuvent être manipulées dans le code du front-end avec process.env.nom_variable. (cf. config.js dans l'archive)
1°/ Authentification
A l'heure actuelle, de nombreuses applications web ne gèrent plus elles-mêmes l'authentification de leur utilisateurs. Elles font appel à des web services que proposent bon nombres d'entreprises, notamment google, amazon, microsoft, etc. Ce mécanisme n'est cependant pas applicable lorsque les accès aux parties privées nécessitent des informations qui ne sont pas disponibles dans un compte de type google/microsoft. C'est souvent le cas avec les applications internes à une entreprise. Dans ce cas, il faut utiliser les bases de données utilisateurs de l'entreprise. NB: ces BdD peuvent malgré tout être externalisées dans un cloud et accessibles via des web services, mais est-ce judicieux ?
Pour cela, soit l'application web fait elle-même l'authentification en accédant directement à la base données, soit elle fait appel à un serveur d'authentification interne, par exemple un serveur CAS (comme à l'université). Comme on est dans le cadre d'une application web, s'exécutant au sein d'un navigateur, l'authentification se fait à priori sur la base de requête http. C'est pourquoi les principes d'authentification restent généralement les mêmes :
- une page permet de saisir un login + mot de passe.
- le couple est envoyé au serveur via une requête POST, et en principe une connexion cryptée, afin que le couple ne soit pas lisible directement en cas d'interception.
- le serveur vérifie (soit lui-même, soit auprès d'un autre serveur d'authentification) que le couple est valide.
- si c'est le cas, le serveur renvoie au client une (ou plusieurs) information lui signifiant qu'il est bien logué. Sinon, il renvoie une erreur.
Historiquement, le contenu de ces informations a été très divers, même si le principe restait le même : utiliser une ou plusieurs valeurs créés par le serveur, que le navigateur va renvoyer à chaque requête. Le serveur peut ainsi vérifier si la requête doit être bloquée car le navigateur n'envoie pas des valeurs valides. L'un des premiers type de valeur utilisé dans les sites en php a été un identifiant de session, souvent sous la forme d'une chaîne de caractères de type uuid. Cet identifiant était soit renvoyé "en clair" dans l'URL des requêtes suivantes, soit dans le corps de la requête, soit sous forme de cookie. A l'heure actuelle, on utilise plutôt les Json Web Token, dont le contenu est crypté donc non lisible directement côté navigateur.
En revanche, la façon dont le serveur renvoie renvoie les informations a pris essentiellement 2 formes :
- cookie (via l'entête de réponse Set-cookie)
- données au format xml/json, contenu dans le corps de la réponse à la requête http d'authentification.
L'avantage des cookies est qu'ils sont automatiquement renvoyés par le navigateur lors des requêtes suivantes au serveur. Cependant, il faut prendre garde à la sécuriser si l'on ne veut pas qu'ils soient accessibles et piratables, via du code javascript. Si on reçoit du xml/json, il faut stocker les informations en mémoire, ce qui signifie qu'elles sont forcément accessibles via du javascript. Il faut également penser à renvoyer ces informations lors de chacune des requêtes suivantes. En apparence, la solution des cookies semble plus simple et efficace mais on va voir que la meilleure solution consiste a mixer les 2 moyens.
2°/ Les JSON Wen Token (JWT)
2.1°/ principe
Un JWT est simplement un objet JSON contenant une partie donnée et une partie indiquant la validité de cette donnée. La donnée est cryptée grâce à une clé symétrique qui n'est connue que par l'émetteur du JWT, donc généralement le serveur.
Les données stockées dans le JWT peuvent être aussi diverses qu'un identifiant de session, un nom d'utilisateur, des informations liées à l'accès à l'application web, etc. C'est le serveur qui décide de ce qu'il y a à l'intérieur et le navigateur ne peut en principe pas décrypter ses informations. Si le JWT est modifié d'une quelconque façon, par exemple par un pirate qui aurait réussi à se le procurer, les informations stockées dedans restent normalement inaccessibles et toute tentative de modification du JWT provoquera une erreur au niveau du serveur qui, à priori, n'arrivera pas à le décrypter correctement.
2.2°/ failles classiques
En revanche, le simple fait de récupérer le JWT peut donner au pirate l'occasion d'usurper l’identité du propriétaire légitime, selon la façon dont le serveur est implémenté. En effet, s'il suffit d'envoyer un JWT en cours de validité pour accéder aux pages privées d'un site, alors en voler un autorise un piratage facile.
2.2.1°/ faille XSS
Une des façons les plus courantes de récupérer un JWT est d'explorer l'un des espaces de stockage locaux du navigateur. Par exemple, l'espace local représenté par la variable localStorage en javascript, permet de stocker des clés, associées à des valeurs. On peut donc stocker un JWT en l'associant à un nom.
Malheureusement, n'importe quel code javascript s'exécutant au sein du navigateur permet d'accéder au localStorage et donc récupérer les données liées à une clé, pourvu que l'on connaisse le nom de la clé. Pour trouver ce dernier, il suffit d'enregistrer le code javascript de l'application web et de faire une recherche sur localStorage.
Pour exécuter un code JS accédant au localStorage, il suffit de faire un peu de "social engineering" et persuader un utilisateur de l'application de cliquer sur un lien vers un site, ce dernier envoyant au navigateur une page avec du JS accédant au localStorage, pour l'envoyer au pirate, donc avec le JWT dedans. Le pirate peut donc se faire passer pour l'utilisateur. Ce type de faille est nommée XSS = Cross Site Scripting car un utilise un site fournissant un script JS permettant d'attaquer un autre site écrit en JS.
Il est également possible que l'application contienne une faille permettant au pirate d'enregistrer des données contenant du JS, dans les Bdd utilisées par le site. Quand un utilisateur demande une page qui affiche ces données, le navigateur exécutera le code JS, qui accédera au localStorage pour envoyer le JWT de l'utilisateur. Ce type de faille utilise le principe de " l'injection de code" puis le XSS.
2.2.2°/ faille XSRF
XSRF = Cross Site Request Forgery.
Cette faille est utilisable lorsque le JWT est stocké dans un cookie, au lieu du localStorage. La première précaution à prendre est de rendre les cookies non accessibles via du JS. Cela se fait dans le code du serveur qui envoie le cookie (cf. attribut httpOnly). Si cette précaution n'est pas prise, alors un pirate peut utiliser directement une faille de type XSS pour récupérer le cookie.
Sinon, il faut également que le navigateur accepte de stocker ce cookie. En effet, si un navigateur visite un site A, qui fait appel à une API B avec un nom de domaine différent, et que B envoie un cookie au navigateur, ce dernier refuse par défaut le cookie. Il faut que B configure l'attribut sameSite du cookie afin de forcer la main au navigateur. Ensuite, chaque fois que le navigateur fera une requête HTTP vers B, le cookie sera automatiquement renvoyé.
C'est justement ce renvoi automatique (nécessaire si l'API utilise un cookie JWT pour authentifier les requêtes) qui peut être exploité par un pirate :
- un utilisateur consulte un serveur web A, qui lui envoie une application vuejs.
- Cette application tire ses données d'un autre serveur B, auprès duquel il faut d'abord faire une requête d'authentification. Dans ce cas, B envoie un cookie avec le JWT dedans.
- l'utilisateur est encouragé à accéder à site pirate C.
- C envoie au navigateur une page contenant du JS et qui fait un requête vers B, avec bien entendu des données à même d'endommager ou corrompre B.
- le code JS est exécuté par le navigateur et comme la requête va vers B, le cookie contenant le JWT est automatiquement envoyé.
- B reçoit la requête et comme le JWT est valable, si B est mal protégé/implémenté, il va stocker les données qui vont le faire planter, ou bien introduire une faille XSS.
2.3°/ principes pour limiter les XSS + XSRF
Il n'existe malheureusement pas de méthode infaillible mais on peut remarquer que les deux solutions (localStorage et cookie) ne sont pas sensibles au même type de faille. Une solution à peu près sécurisée consiste donc à mixer les deux principes :
- un token dit xsrf est généré aléatoirement sous forme d'un hashtag assez long, et transmis au navigateur qui le stocke dans le localStorage.
- un jwt est généré, avec comme données un identifiant de session/utilisateur + le token xsrf
- le jwt est transmis au navigateur sous la forme d'un cookie, sans oublier de fixer ses champs httpOnly (afin d'éviter qu'il soit lisible grâce à du code JS), secure, signed à true, et sameSite à none (pour que le navigateur accepte de le stocker)
Quand le navigateur envoie une requête au serveur :
- le cookie contenant le jwt est automatiquement transmis,
- le token xsrf est récupéré dans le localStorage et est ajouté explicitement (via du code JS) aux entêtes (= headers) de la requête.
Quand le serveur reçoit une requête :
- il récupère le jwt, le décrypte et récupère le token xsrf contenu dedans,
- il récupère dans les entêtes le token xsrf
- il compare les 2 tokens xsrf ainsi obtenus et s'il constate une différence, renvoie une erreur au navigateur,
- sinon, il récupère le reste des informations dans le jwt, vérifie si elles sont valides et si ce n'est pas le cas, renvoie une erreur au navigateur.
ATTENTION : Il faut bien comprendre que cette méthode n'est pas infaillible puisqu'il est toujours possible via une faille XSS de récupérer le token xsrf de l'utilisateur, puis d'utiliser une faille XSRF. Cependant, cela limite fortement la probabilité qu'une telle attaque réussisse.
2.4°/ Rafraîchir un JWT : les pours et les contres
Pour limiter les possibilités d'attaque, on lit fréquemment qu'il convient surtout de limiter le temps de validité d'un JWT. C'est très facile quand le JWT est dans un cookie puisque la durée de vie de ces derniers est fixée par le serveur qui envoie le cookie. Par exemple, si un JWT est valide pendant seulement une minute, un pirate n'a quasi aucune chance de récupérer le token xsrf via une faille XSS pour ensuite lancer une attaque type XSRF.
Cependant, cela impliquerait de se reloguer toutes les minutes, ce qui est impensable. De ce fait, on doit mettre en place un mécanisme permettant de "rafraîchir" le JWT :
- Quand l'utilisateur se logue, il reçoit un JWT sous forme de cookie, un token xsrf ET un token de rafraîchissement qui sont stockés dans le localStorage ou en mémoire dans les données de l'application (par ex, le store)
- Par la suite, si le serveur reçoit une requête avec seulement le token xsrf, cela veut dire que le cookie n'est plus valide, et il rejette la requête en renvoyant un erreur identifiable par l'application cliente.
- Quand elle reçoit une telle erreur, elle envoie une requête avec le token de rafraîchissement et le serveur renvoie un cookie JWT.
A noter que le token de rafraîchissement a également une validité, généralement assez longue (plusieurs minutes/heures) par rapport à celle du JWT.
Malheureusement, si les token xsrf et rafraîchissement sont stockés dans le localStorage, une faille XSS permet à un pirate d'accéder au contenu du localStorage. Il peut donc demander lui-même un rafraîchissement et obtenir un JWT valide. On aboutit donc à une situation presque pire puisque le pirate peut se faire passer pour l'utilisateur, comme avec une faille XSS. Même si on stocke le token de rafraîchissement dans le store, un pirate chevronné analysera le code JS de l'application et réussira à accéder à la variable contenant le token.
Heureusement, il existe des solutions pour compliquer la tâche aux pirates. Par exemple :
- le serveur vérifie que la demande de rafraîchissement vient bien de la même IP que celle utilisée lors du login (attention, l'usurpation d'IP n'est pas très compliquée)
- à chaque rafraîchissement, le hashtag du token est régénéré et renvoyé au client. Si le rafraîchissement a lieu toutes les minutes, le pirate a donc une minute pour récupérer le token et l'exploiter (attention, c'est faisable).
- stocker le token dans un cookie comme le JWT avec une validité modérée (par ex, 1h). Même s'il est renvoyé à chaque requête, il ne sera réellement utilisé que lorsque l'utilisateur fait explicitement une requête de rafraîchissement. Si un pirate a déjà réussi à subtiliser le token xsrf, il n'aura pas le cookie de rafraîchissement et donc sera incapable de récupérer un JWT valide.
2.5°/ Encore plus de sécurité ?
Enfin, il est également possible d'ajouter d'autres précautions, plus exotiques :
- stocker le token xsrf dans sessionStorage : dès que la navigateur est fermé, sessionStorage est supprimé, ce qui implique que l'utilisateur doit de nouveau se loguer.
- générer le nom de la clé associée au xsrf token au niveau du serveur pour l'envoyer au navigateur : le pirate qui veut récupérer le xsrf token ne peut pas connaître à l'avance le nom de la clé et doit donc faire une analyse complète du code JS.
3°/ mise en place avec vuejs.
On suppose que le serveur est une API de type REST, avec une route /login. La méthode POST est utilisée pour envoyé un objet json contenant le login et le mot de passe fournis par l'utilisateur.
3.1°/ contraintes liées à l'utilisation des API
Les navigateurs modernes sont très restrictifs avec les requêtes asynchrones. En effet, quand les pages actuellement consultées dans le navigateur proviennent d'un site A, et qu'une de ces pages fait une requête asynchrone vers un site B, le navigateur peut refuser d'en charger le contenu. C'est le mécanisme CORS (Cross Origin Resource Sharing) intégré au navigateur qui va autoriser ou non le contenu en fonction des entêtes fournies par B. Attention : une simple différence de n° de port est significative pour CORS. Par exemple, quand on test en local un site A fourni par localhost:8080 et que l'API REST est accessible par localhost:4567, alors CORS considère que ce sont 2 origines différentes.
Par défaut, si le site B ne fait rien pour envoyer les bonnes entêtes dans les réponses aux requêtes du client, le navigateur bloquera le contenu, y compris les cookies qui ne seront pas sauvegardés dans la mémoire du navigateur.
Par exemple, dans un serveur écrit en node + express, on peut utiliser le module cors afin de positionner correctement les entêtes :
const express = require('express');
const cors = require("cors");
const app = express();
var corsOptions = {
origin: [ /.*$/ ], // ATTENTION : toute origine est acceptée = trou de sécurité potentiel
credentials: true,
allowedHeaders: "x-xsrf-token, Origin, Content-Type, Accept",
};
app.use(cors(corsOptions));
...
Explications :
- origin permet de sélectionner quels sont les origines acceptées pour que CORS ne bloque par la réponse. Dans le cas présent, une requête asynchrone venant de n'importe quelle origine sera valide. Le serveur traitera la requête, renverra le résultat avec une entête signalant au navigateur que ce résultat est valide.
- credentials positionné à true permet au serveur d'indiquer au navigateur que les cookies envoyés sont valides et doivent être stockés.
- allowedHeaders permet au serveur de spécifier quelles entêtes il accepte. Dans le cas présent, x-xsrf-token est l'entête que le navigateur utilisera pour envoyer le token xsrf. Ce n'est pas une entête définie par HTTP. On peut donc utiliser n'importe quel autre nom.
3.2°/ l'application SPA
Le code de démonstration n'utilise pas toutes les astuces destinées à compliquer la tâche à un pirate. Pour résumer, il utilise :
- un cookie pour le JWT
- le localStorage pour stocker les tokens xsrf et de rafraîchissement.
3.2.1°/ configuration de vue
Afin de faciliter le passage d'une version de développement à une version de production, il est utile de définir deux fichiers donnant l'URL de l'API, en mode dev. ou bien prod. Ces 2 fichiers sont à mettre à la racine du projet. Exemple :
fichier .env.development
VUE_APP_API_ENDPOINT=https://localhost:4567/authapi
fichier .env.production
VUE_APP_API_ENDPOINT=https://myapi.domain.fr:443/authapi
La variable VUE_APP_API_ENDPOINT peut ensuite être utilisée dans le reste du code, grâce à process.env.
Pour simplifier encore, il est possible de créer un fichier général de configuration de l'application que l'on importe dans la plupart des autres fichiers. Par exemple :
fichier config.js
export default {
urlAPI: process.env.VUE_APP_API_ENDPOINT
}
On peut ensuite utiliser cette variable comme base pour les requêtes d'axios. Par exemple, dans le fichier axios.service.js :
import axios from 'axios'
import Config from '../commons/config'
...
// create a special axiosAgent agent that works with the apidemo API
const axiosAgent = axios.create({
baseURL: Config.urlAPI,
withCredentials : true,
});
3.2.2°/ les services
Le plus simple et fonctionnel consiste à créer différents fichiers représentant les "services" fonctionnels. Par exemple :
- axios.service.js : contient le code qui va créer l'agent axios comme dans les TDs précédent, et qui utilise un intercepteur pour envoyer le token xsrf dans toutes les requêtes sous forme d'une entête. Le fichier contient également les fonctions permettant de faire des requêtes get, post, patch, etc, ainsi que la fonction qui gère les erreurs. Toutes ces fonctions sont modifiées plus ou moins, pour permettre de gérer le rafraîchissement du jwt.
- auth.service.js : contient le code qui va faire la requête axios pour se loguer et pour rafraichir le jwt.
- user.service.js : contient le code permettant d'enregistrer un nouvel utilisateur, ou bien d'obtenir ses informations.
Comme dit précédemment, le jwt étant stocké dans un cookie, il sera automatiquement envoyé à chaque requête, pourvu que le navigateur soit configuré pour cela. Par défaut, les cookies ne seront pas envoyés à des sites d'une autre origine. Lors de l'envoi d'un requête il faut donc dire explicitement de les envoyer. On peut configurer l'agent axios pour que ce soit fait automatiquement. Par exemple, dans axios.service.js, on écrit :
import axios from 'axios'
import https from 'https' // pour faire des requêtes en https.
const myaxios = axios.create({
httpsAgent: new https.Agent({rejectUnauthorized: false}),
withCredentials: true, // envoi auto. des cookies à d'autres origines
});
Quant au token xsrf, comme il est possible de créer artificiellement des entêtes aux requêtes HTTP, il suffit d'en ajouter une dont la valeur est le token xsrf, et d'envoyer cette entête à chaque requête axios.
Pour cela, le plus simple est d'utiliser les "intercepteurs" axios. Ils permettent de définir des fonctions qui seront appelées automatiquement dans certaines situations, notamment quand on veut envoyer une requête. Par exemple :
myaxios.interceptors.request.use(
config => {
return {
...config,
headers: {
...AuthService.authHeader()
},
};
},
error => Promise.reject(error)
);
La méthode authHeader() renvoie simplement un objet du style { x-xsrf-token : "..." }, où la valeur provient du localStorage, si elle existe. Sinon, on ne renvoie rien.
Grâce à cet intercepteur, on ajoute l'entête x-xsrf-token à toutes les requêtes vers le serveur, à partir du moment où l'authentification a été réussie et que l'on a reçu une valeur pour le token xsrf.
3.2.3°/ le store
Le store vuex va permettre de conserver les informations de connexion, notamment les token xsrf, et si l'utilisateur est logué ou non. Cette information est généralement essentielle pour faire de l'affichage conditionnel de contenu.
Pour cela, il convient de créer un store modulaire, avec un module pour gérer l'authentification, et d'autres pour gérer les données applicatives. Pour l'authentification, on peut créer un fichier auth.js, avec :
- un state contenant l'état d'authentification (logué ou non, token xsrf, ...)
- 3 mutations pour mettre à jour cet état : log réussi, log raté, logout.
- 2 actions :
- login, qui appelle le service de login puis selon le résultat la mutation log réussi ou log raté
- logout, qui appelle la mutation logout.
3.2.4°/ Le router
Les routes du front-end sont définies comme dans le TD 1, avec notamment un mécanisme qui empêche de suivre des routes qui nécessitent une authentification réussie.
3.2.5°/ Le composant d'enregistrement
Ce composant fournit une interface permettant de créer un nouvel utilisateur. Il sert uniquement à montrer comment utiliser l'API recaptcha fournie par google, au travers d'un module npm nommé vue-recaptcha.
Pour résumer, l'utilisation de ce module nécessite de créer une paire de clé sur le site de google qui gère recaptcha : https://www.google.com/recaptcha/
Avec un compte google, il est possible de créer cette paire de clé. L'une de ces clés doit être utilisée dans le front-end et l'autre dans le back-end. Il n'y a effectivement pas de possibilité de faire avec uniquement le front. En pratique, quand on valide le captcha, il faut ensuite envoyer au back-end le résultat de cette validation. Ce dernier fait ensuite appel à l'API google recaptcha pour vérifier si la validation est correcte ou non.
Dans le cas présent, le formulaire d'enregistrement fait appel à une route du back-end, en envoyant un login, mot de passe et nom de héro, plus de résultat de la validation du captcha. Ensuite, le back-end interroge l'API google et si tout est bon, il peut ensuite vérifier les informations fournies avant de créer le nouvel utilisateur.
3.3°/ Démonstration
NB : l'API est réglée pour que le JWT expire au bout de 30 secondes.
- Utiliser le menu tirroir pour essayer d'afficher le profil utilisateur courant : la route est ne peut pas être suivie car il faut au préalable être logué.
- Utiliser le bouton login pour afficher le composant d'authentification : login = toto, mot de passe = azer. Après cela, le profil peut être affiché.
- De même pour obtenir la liste de tous les utilisateurs.
Remarque :
- La console affiche un warning, à propos d'un champ login qui ne peut être trouvé. C'est un problème classique lorsqu'un composant fait appel à un service de récupération des données asynchrone lorsqu'il est monté.
- Dans le cas présent, UserEdit définit sa fonction mounted() pour aller chercher sur l'API les informations de l'utilisateur actuellement logué.
- Or, cette requête permet de mettre à jour un objet du store qui à l'origine vaut null et qui après la requête, contient entre autre le login de l'utilisateur.
- Quand UserEdit est monté, il accède à cette variable, qui vaut null, d'où le warning.
- Dès que la requête est complétée, la valeur de l'objet dans le store change, donc vuejs rafraîchit tous les composants affichant des champs de cet objet.
- Pour éviter ce warning, il faudrait écrire le composant en tenant compte du fait que l'objet dans le store vaut null, par exemple en modifiant la première balise comme suivant : <v-card v-if="user !== null">
- Utiliser le menu pour revenir à l'écran d'accueil.
- Attendre 40 secondes, puis réafficher le profil : l'application affiche un dialogue d'erreur et revient au composant de login.
- Pour ces différentes requêtes, l'onglet réseau de l'inspecteur permet de voir le cookie JWT ainsi que les entêtes contenant les token xsrf.
4°/ Bonus : installer le back-end.
Le back-end repose sur une BdD mongodb v5. Il faut donc installer ce sgbd en premier lieu.
- Le code du back-end peut être téléchargé [ ici ].
- Une fois l'archive décompactée, un répertoire authapi est créé.
- Aller dans ce répertoire, et exécuter : npm install
- Une fois l'installation terminée : npm run serve
- Détails
- Écrit par Super Utilisateur
- Catégorie : R4A.10 - Compléments web (vuejs)
- Affichages : 533
1°/ Le développement mobile en JS
Il existe à l'heure actuelle plusieurs approches pour créer des applications mobiles à l'aide d'environnements JS. On peut globalement les répartir en 3 catégories :
- celles qui permettent de produire une application totalement native. Dans le cadre de vuejs, on peut citer, vue-native (qui produit du code pour react-native) et nativescript-vue,
- celles dites hybrides, qui utilisent une webview pour simuler un navigateur et exécuter le code de l'application, mais en utilisant des plugins qui permettent d'accéder nativement au matériel. Les principaux plugins sont capacitor et cordova et les environnements les plus connus sont ionic-vue et quasar.
- celles qui utilisent uniquement les capacités de navigateurs modernes pour accéder au matériel, mais qui proposent tout de même une expérience utilisateur similaire aux application natives, grâce à la gestion d'un cache pour les ressources, ce qui permet d'utiliser l'application hors-ligne. On appelle ce type d'application PWA, pour Progressive Web Application. Il existe un plugin pwa pour vue.
Remarque : grâce à capacitor, il est possible de mixer hybride et pwa puisqu'il est capable de détecter si le matériel est accessible nativement et si ce n'est pas le cas, d'utiliser les capacités du navigateur.
- Ce TD est découpé en 2 parties : la première consacrée à quasar, couplé à cordova ou capacitor, et la deuxième consacrée à ionic + capacitor.
- Ces deux environnements sont relativement identiques dans la façon de créer une application :
- on utilise un set de composants graphiques propre à l'environnement,
- on utilise android studio pour tester dans un émulateur ou bien sur un téléphone réel l'application,
- on peut faire du développement "interactif", comme avec une application web SPA classique servie par un serveur web de développement,
- Il y a malgré tout des différences entre ces 2 solutions :
- ionic est plutôt pensé pour développer en typescript, et plutôt js "classique" pour quasar,
- quasar propose un visuel de composants graphique unique, plutôt dans le style material design (donc orienté android), alors que ionic propose un look différent selon l'architecture cible.
- créer un projet ionic-vue est un peu plus simple car il y a des installations automatiques. En revanche, on peut moins facilement configurer la création du projet que sous quasar.
- quasar permet à priori de créer bien plus de types d'application que ionic qui est avant tout fait pour des applications sur mobile (même s'il peut être utilisé pour d'autres architecture).
- quasar est plus vieux, plus stable, mieux documenté, plus fourni en composants que ionic-vue.
2°/ Mise en place logicielle préalable
2.1°/ Installation d'android studio
- Quelle que soit l'environnement choisi, il faut auparavant installer tout ce qui concerne les plateforme natives, donc xcode ou android studio.
- Ce qui suit concerne uniquement android, qui ne pose aucune contrainte matérielle telle que avoir un mac.
Remarque : les machines du département sont déjà installées avec la configuration décrite ci-dessous. Vous ne devez donc suivre ces étapes que pour faire l'installation sur une machine personnelle.
- La première étape consiste à télécharger Android-studio : http://developer.android.com/studio
- Vous obtenez une archive avec un nom du type : android-studio-2023.1.1.28-linux-tar.gz
- Dans un terminal, en tant que root, lancez les commandes suivantes :
mv android-studio-2023.1.1.28-linux-tar.gz /usr/local/
cd /usr/loca/
tar zxf android-studio-2023.1.1.28-linux-tar.gz- Cela crée un répertoire /usr/local/android-studio, dans lequel se trouve les binaires de l'application
- Il faut maintenant configurer le logiciel pour un utilisateur "normal", notamment afin de télécharger le Sdk.
- Dans un terminal, allez dans votre home directory et lancez : /usr/local/android-studio/bin/sutio.sh
- L'installateur affiche une série de fenêtre pour choisir la configuration. après avoir accepté la licence, l'installation du Sdk se lance.
- Cela crée un répertoire Android/Sdk dans votre home directory.
- Il faut maintenant télécharger différents outils et plateformes de développement
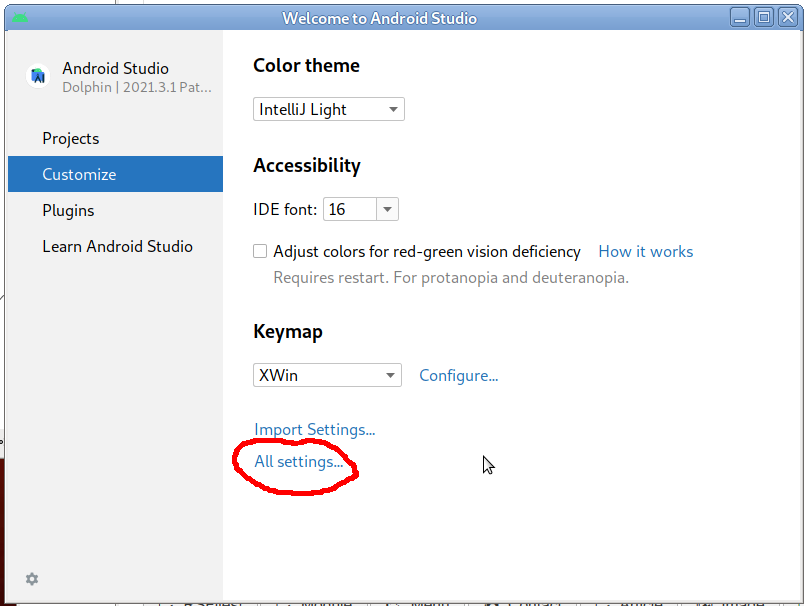
- Dans la fenêtre d'accueil d'android studio, choisir "Customize" puis "All settings", comme indiqué dans l'image ci-dessous
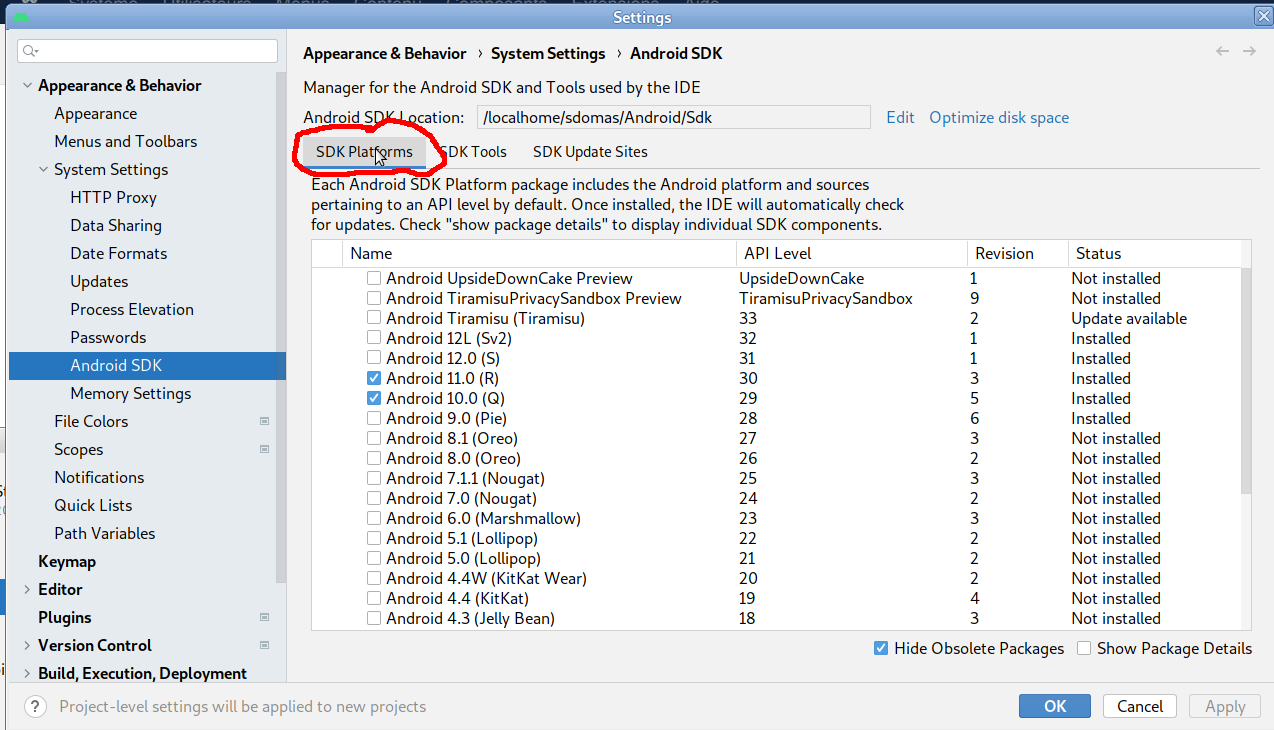
- Dans la fenêtre de configuration, aller dans "Appearance & Behaviour" > "System settings" > "Android SDK", puis cliquer sur l'onglet "SDK Platforms" comme indiqué sur l'image ci-dessous.
- Ensuite, sélectionner certaines plateformes à installer. Seules les versions 10 et 11 peuvent être cochées, car cordova et capacitor ne sont pour l'instant pas compatibles avec des versions plus récentes.
- ATTENTION ! les versions 10 & 11 ne sont pas disponibles sur tous les téléphones. Si vous voulez créer une application plus "compatible", il faudra installer des versions de plateforme plus anciennes (V9 voire V8)
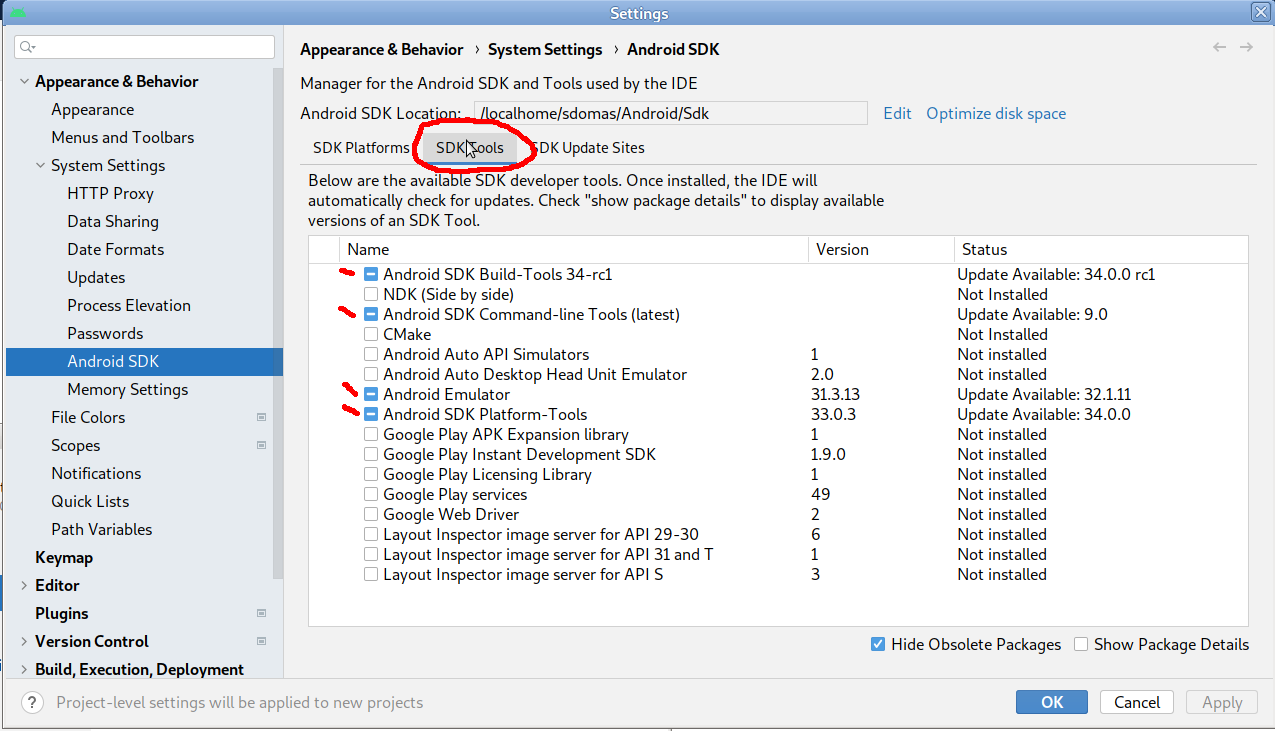
- Cliquez ensuite sur l'onglet "SDK Tools" et si besoin cochez les cases Android SDK Build-Tools, Android SDK command-line Tools, Android Emulator, Android SDK Platform-Tools, comme indiqué dans l'image ci-dessous.
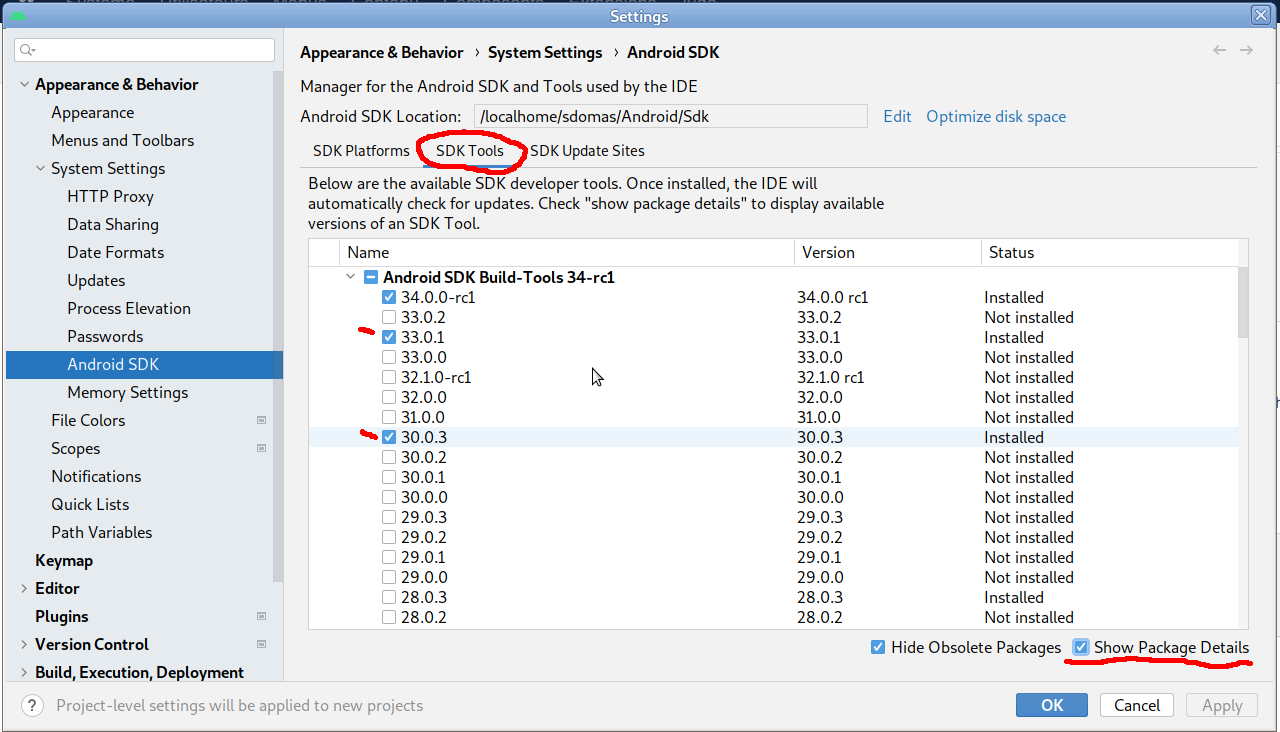
- Cochez la case "Show Package Details" et vérifiez que les Build-Tools version 30.0.3 et 33.0.1 sont bien cochés, comme indiqué dans l'image ci-dessous
- Cliquez ensuite sur "Apply" pour valider les choix. Après acceptation de la licence, les téléchargements commencent.
- Il faut à présent créer au moins un simulateur de téléphone.
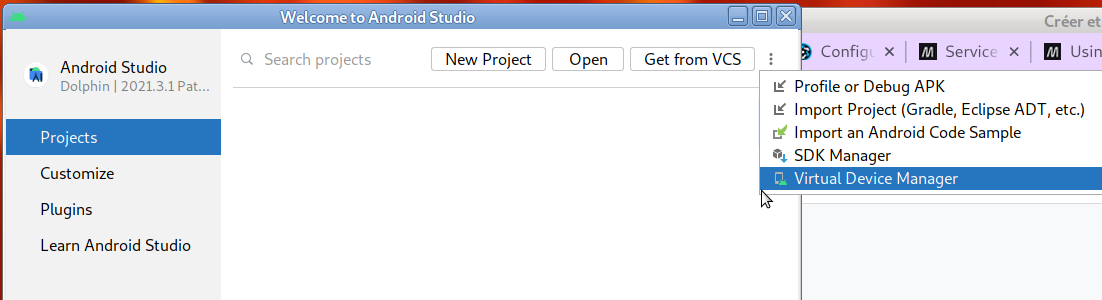
- Pour cela, fermer la fenêtre de configuration pour revenir à l'écran d'accueil et cliquer sur "Project" puis sur l'icône paramètres en haut à droite (3 points verticaux) et choisir "Virutal Device Manager", comme indiqué sur li'mage ci-dessous.
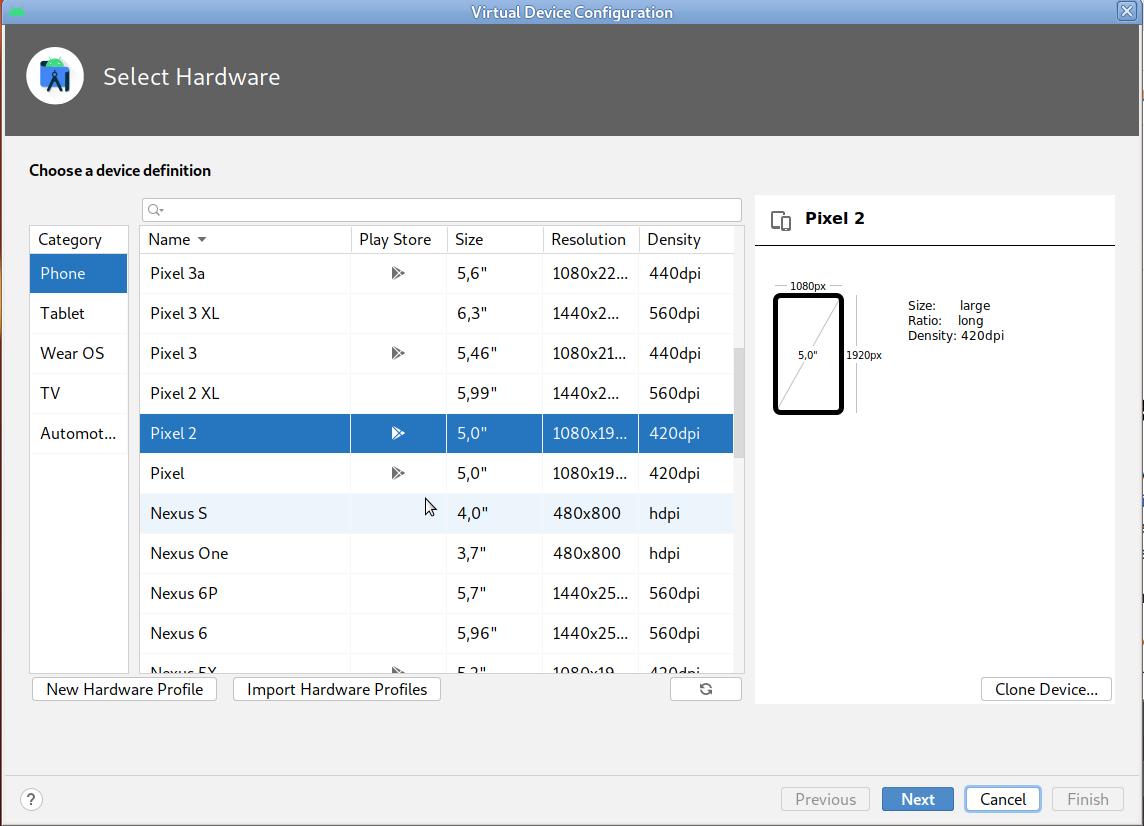
- Dans le fenêtre, cliquer sur le bouton "Create Device", puis choisir un modèle, par exemple le Pixel 2, comme indiqué dans l'image ci-dessous
- Cliquer sur "Next", puis choisir un OS pour le simulateur. Il est fort possible que l'OS ne soit pas déjà disponible, auquel cas, il faut le télécharcer en cliquant sur la flèche à côté du nom, comme indiqué dans l'image ci-dessous.
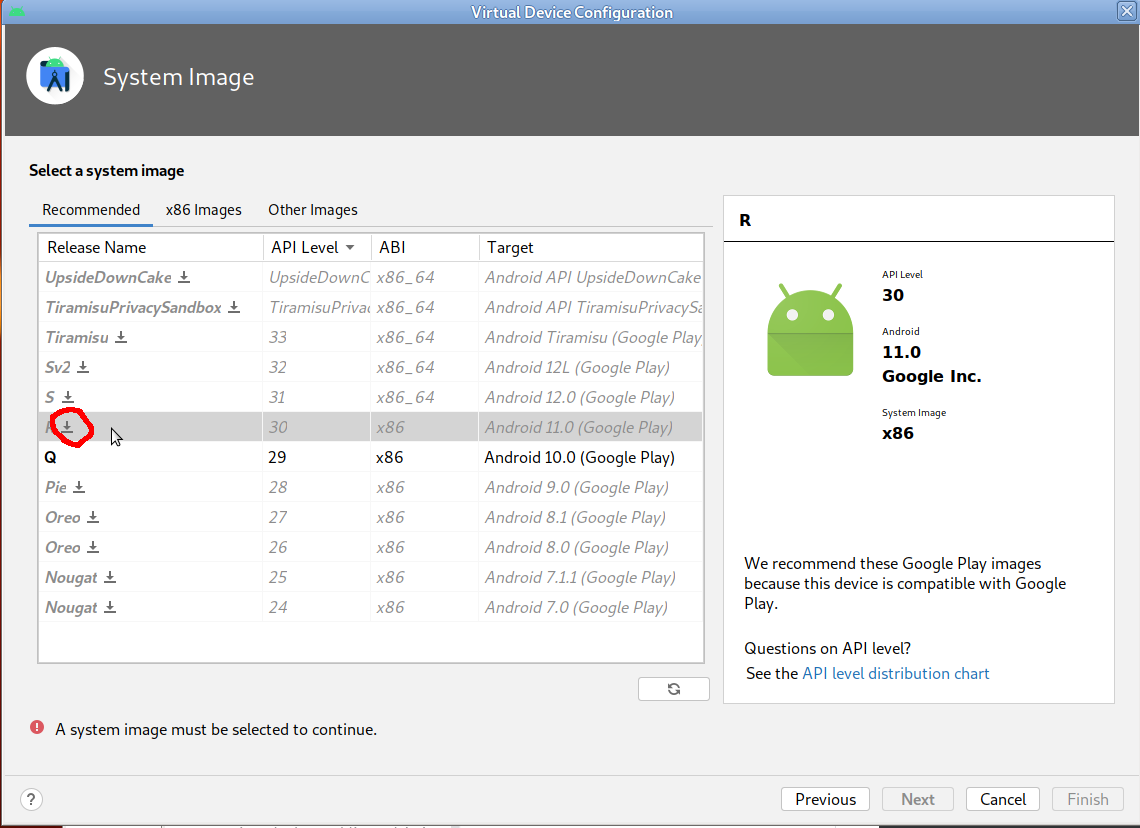
- Une fenêtre s'ouvre puis le téléchargement commence.
- Une fois terminé, terminer la configuration, notamment en donnant un nom au simulateur, son orientation, etc.
- Une fois la création terminée, le simulateur est disponible dans la liste de l'écran d'accueil.
- Pour vérifier que tout fonctionne, cliquez sur la flèche pour lancer l'émulateur. Une fenêtre ressemblant au téléphone apparaît, puis après quelques dizaines de secondes, l'écran d'accueil android s'affiche.
- Il est ensuite possible d'interagir comme sur un téléphone réel, bien que certaines opérations fassent "ramer" l'émulateur.
- La dernière étape consiste à indiquer au système d'exploitation les chemins d'accès au SDK de android-studio.
- Pour cela, il faut éditer le fichier .bashrc (ou .profile, selon votre cas) et ajouter à la fin, quelque chose du genre :
################################
# Android SDK
###############################
export ANDROID_HOME="/home/toto/Android/Sdk"
export ANDROID_SDK_ROOT="/home/toto/Android/Sdk"
export PATH=$PATH:$ANDROID_SDK_ROOT/cmdline-tools/latest/bin:$ANDROID_SDK_ROOT/platform-tools:$ANDROID_SDK_ROOT/emulator- Il faut bien entendu remplacer /home/toto par le chemin vers votre propre répertoire Android/Sdk
2.2°/ Installation de gradle
- Pour compiler les projet quasar, il faut faire appel au logiciel gradle.
- Malheureusement, le plugin gradle installé avec le sdk android n'est pas directement utilisé par quasar.
- Il faut donc installer gradle séparément.
- Pour cela, d'aller sur https://gradle.org/releases/ et de télécharger l'archive binary-only de la version 8.2 ou supérieure.
- En tant que root, copier l'archive téléchagée gradle-8.2-bin.zip dans /usr/local et la décompacter.
- Ensuite, il suffit d'ajouter le chemin d'accès à l'exécutable de gradle dans son .bashrc :
################################
# Gradle
###############################
export PATH=$PATH:/usr/local/gradle-8.2/bin
2.3°/ Installation des paquets node pour quasar, cordova
- Il suffit d'utiliser npm pour faire un installation globale :
npm install -g @quasar/cli
npm install -g cordova
2.4°/ Utilisation de la version 11 de Java
- Le plus gros piège pour créer des projets avec cordova est qu'il faut utiliser la bonne version de Java.
- Même si le Sdk android n'est pas basé sur une version fixée de Java, Android studio est en revanche fourni avec la v11 de Java.
- Au cas où il n'y ait pas de JDK/JRE installé sur votre machine, il est donc possible d'exécuter android studio grâce à cette V11 de Java.
- Cependant, il est fréquent qu'une machine soit installée avec un JDK général au système très récent, par exemple en utilisant les paquets openjdk-17-jdk.
- Si votre machine est effectivement installée avec la v17, voire plus récente, cela va poser des erreurs lors de la compilation de votre projet quasar.
- Il faut obligatoirement utiliser la v11 et donc l'installer si ce n'est déjà fait : apt-get install openjdk-11-jdk
- Sous debian, il est facile de passer d'une version à une autre, en étant root
update-alternatives --config java- Il suffit de choisir le n° de menu correspond à la v11.
3°/ Création d'un projet quasar
3.1°/ Initialisation du projet
- Le plus simple est de partir d'un projet d'exemple créé avec les commande quasar :
npm init quasar- Le générateur de projet vous pose différentes questions, notamment sur les versions des différents environnements/outils à utilisé
- La plupart du temps, il suffit de prendre la réponse déjà sélectionnée, mais voici une liste des réponses "conseillées" :
- 1ère question : App with Quasar CLI
- 2ème : mettez le nom de votre projet
- 3ème question : Quasar v2
- 4ème question : Javascript (sauf si vous préférez le typescript)
- 5ème question : Quasar App CLI with Webpack. ATTENTION : il est souvent conseillé d'utiliser Vite comme gestionnaire de construction du projet au lieu de webpack. Malheureusement, même si Vite bien plus performant que webpack, il y a des problèmes de compatibilité dès lors que l'on utilise des plugins capacitor. C'est pourquoi, il faut choisir webpack.
- 6ème question : à priori le nom de votre projet
- 7ème question : le nom de votre application, qui sera utilisé comme nom lors de l'installation sur mobile.
- 8ème, 9ème question : ce que vous voulez
- 10ème : Sass with CSS syntaxe
- 11ème question : utilisez les flèches haut/bas puis espace pour sélectionner des plugins. Normalement, ESLint est déjà sélectionné. Si vous avez besoin d'un store, il est conseillé d'utiliser Pinia, qui remplace Vuex avantageusement, tout en étant quasi similaire au niveau du fonctionnement. Vous pouvez également sélectionner Axios si besoin et Vue-i18n pour mettre en place une application multilangue.
- 12ème question : Prettier ou Standard
- 13ème qestion : Yes, use npm
- Une fois le projet créé, vous pouvez aller dans son répertoire et constater que l'on retrouve à peu près la même structure qu'un projet vuejs classique, avec un router.
- Il y a quelques différences dans les noms de certains répertoires, et bien entendu le fait que les composants sont définis en utilisant la nouvelle syntaxe introduite par la v3 du vujes.
- Il est cependant toujours possible d'utiliser des composants écrits avec la syntaxe de la v2.
- Pour la définition de l'interface utilisateur, quasar repose sur un ensemble de composants relativement semblable à vuetify, y compris dans leur mise en oeuvre.
- Le placement des composants est un peu différent, mais se base quand même sur une logique flexbox, avec des noms de classe css qui permettent de définir des lignes et des colonnes de composants.
- Pour tous les détails de l'API quasar : https://quasar.dev/
3.2°/ Tester l'application SPA dans un navigateur
- Pour lancer un serveur de développement et tester l'application :
quasar dev- Normalement, cela lance directement le navigateur avec l'URL servie (par défaut http://localhost:9000)
- Comme pour les projets classiques, on peut modifier le code et voir en direct les changements.
3.3°/ Construire l'application SPA pour la production
- Pour construire l'application :
quasar build- Cette commande crée un répertoire dist/spa à la racine du projet, avec les sources produits par la compilation.
- Pour tester cette version de production :
// on suppose que l'on est à la racine du projet
cd dist/spa
quasar serve
3.4°/ Et electron ?
- Quasar est très versatile puisqu'il permet de faire du dev. en vue de construire l'applicaiton sous forme d'un exécutable, grâce à electron.
- Pour tester l'application :
quasar dev -m electron- Et pour construire l'executable :
quasar build -m electron- Cette commande crée un répertoire dist/electron à la racine du projet, avec les produits de la compilation.
- Sous linux, le sous-répertoire Packaged contient la version prête à être exécutée.
3.5°/ Tester l'application en mode mobile android avec capacitor
- Il est possible d'ajouter capacitor et les plugins que l'on veut, avant de lancer un serveur de dev.
- Cependant, si cet ajout n'a pas été fait, la commande ci-dessous permet au moins d'installer et configurer la base de capacitor pour que le projet puisse se lancer sous android studio :
quasar dev -m capacitor -T androidRemarque : si ce n'est déjà fait, cette commande va créer un répertoire src-capacitor à la racine du projet.
ATTENTION :
- Selon la version de quasar que vous utilisez, il est possible qu'il crée un projet capacitor avec des paquets npm en version "ancienne", comme la v2. Cela pose de nombreux problème car capacitor en est à la v5 et la plus par des exemples que l'on trouve sont pour la v4 ou supérieure
- Pour vérifier si vous avez la bonne version, il suffit d'aller dans src-capacitor et consulter le fichier package.json. Si vous voyez une ligne du type : "@capacitor/core": "2.0.0", c'est que quasar a utilisé une ancienne version.
- Pour le forcer à utiliser une version récente, par exemple la v5, il faut reinstaller les paquets. Pour cela :
cd src-capacitor
rm -rf node_modules
rm package-lock.json- Ensuite, il faut éditer le fichier package.json et modifier la liste des paquets avec :
"dependencies" : {
"@capacitor/core": "^5.0.0",
"@capacitor/cli": "^5.0.0",
"@capacitor/android": "^5.6.0",
}- Ensuite, il suffit de lancer l'installation : npm install
- Si le projet fait appel à des plugins capacitor tels que la caméra, il faut également les installer. Par exemple, pour utiliser la caméra :
npm install @ionic/pwa-elements
npm install @capacitor/camera
- Lors du premier lancement, un certain nombre de paquets vont être téléchargés, et un projet android studio créé.
- Ensuite android studio se lance automatiquement et vous demande s'il doit "faire confiance" à ce projet.
- En cliquant sur "Trust", le projet est ouvert et il est possible de le lancer avec le simulateur de mobile de votre choix.
- Si vous modifiez un fichier source, les changements provoquent une recompilation et le résultat apparaît directement dans android studio.
3.6°/ Construire l'application mobile pour la production
- Pour construire l'application :
quasar build -m capacitor -T android- Cette commande crée un répertoire dist/capacitor à la racine du projet, avec un sous-sous... répertoire contenant le fichier .apk d'installation.
- Attention, ce fichier est à la base non-signé et ne pourra pas forcément être installé sur un mobile.
- Pour le rendre disponible sur play store, suivre les indications données ici : https://quasar.dev/quasar-cli-webpack/developing-capacitor-apps/publishing-to-store
3.7°/ Et cordova ?
- Cordova étant le prédécesseur de capacitor, il n'a pas tous les avantages et améliorations de ce dernier. Par exemple, quand on accède à un périphérique (matériel ou logiciel) du mobile, capacitor est capable de détecter si celui-ci est disponible et accessible afin d'utiliser un accès natif, et sinon, de passer par les capacités du navigateur, à la façon d'une application PWA.
- Cependant, si cordova est réellement nécessaire, alors il suffit de remplacer le mot-clé capacitor par cordova dans les commandes données ci-dessus.
- La différence est qu'avec cordova, l'émulateur est directement lancé, plutôt que de passer par android studio.
4°/ Exemples
4.1°/ Sources
- Il existe beaucoup de tutoriel pour faire sa première application mobile avec quasar. Voici notamment un lien vers une application pour avoir le cours de crypto-monnaie :
- Cela permet d'illustrer l'accès à une API distante avec Axios, et comme on peut le constater, cela ne change strictement rien par rapport à une application SPA.
- A noter que cette application n'utilise aucun plugin capacitor afin d'utiliser le matériel du mobile.
- Un autre exemple, mais prévu pour la v1 de quasar est disponible ici :
- le tutoriel : https://www.dynamsoft.com/codepool/quasar-qr-code-scanner.html
- le dépôt ici : https://github.com/tony-xlh/Quasar-QR-Code-Scanner
- Cette application utilise notamment l'appareil photo.
- Pour illustrer les plugins de capacitor, il existe également de nombreux tutoriels, notamment sur le site même de capacitor : https://capacitorjs.com/docs/apis
- Capacitor est globalement fait pour être indépendant de l'environnement de développement. Il est donc facile d'adapter les exemples à une application quasar.
- On peut même utiliser le très bon exemple provenant du framework ionic :https://ionicframework.com/docs/vue/your-first-app
- En effet, à part les composants ionic qui changent, la partie capacitor est globalement la même.
4.2°/ mini tutoriel avec prise de photo
- lancer npm init quasar pour créer un projet, en prenant bien garde de sélectionner webpack comme builder.
- la suite suppose que le répertoire du projet est testquasar.
- lancer les commandes suivantes :
cd testquasar
quasar mode add capacitor
cd src-capacitor
rm -rf node_modules
rm package-lock.json
- Si besoin (par ex, version ancienne de capacitor), éditer le fichier package.json et modifier les dépendances avec :
"dependencies": {
"@capacitor/cli": "^5.0.0",
"@capacitor/core": "^5.0.0"
"@capacitor/android": "^5.6.0",
}
- lancer les commandes suivantes :
npm install
npm install @capacitor/android
npm install @ionic/pwa-elements
npm install @capacitor/camera
cd ..
npm install @ionic/pwa-elements
npm install @capacitor/cameraRemarque : il est un peu bizarre mais essentiel d'installer les plugins capacitor aussi bien dans le répertoire dédié à capacitor qu'à la racine du projet. En effet, les sources de l'application se trouvent à la racine du projet et il faut bien que la compilation puisse accéder aux plugins capacitor, sinon la compilation webpack échouera. D'un autre côté, si les plugins ne sont pas présents dans le répertoire de capacitor, c'est la compilation pour android qui ne produira pas une application fonctionnelle.
- Editer le fichier quasar.config.js et trouver un champ boot. Modifier ce champ avec :
boot: [
'capacitor'
],- Créer un fichier src/boot/capacitor.js avec dedans :
import { defineCustomElements } from '@ionic/pwa-elements/loader'
export default () => {
defineCustomElements(window)
}- Editer le fichier src/layouts/MainLayout.vue :
- vers la fin du template :
<q-page-container>
<q-btn color="primary" label="Get Picture" @click="captureImage" />
<img :src="imageSrc">
<router-view />
</q-page-container>-
- au début de la partie <script>, ajouter les imports :
import { Camera, CameraResultType } from '@capacitor/camera'-
- modifier la fonction setup() comme suivant :
setup () {
const leftDrawerOpen = ref(false)
const imageSrc = ref('')
async function captureImage () {
const image = await Camera.getPhoto({
quality: 90,
allowEditing: true,
resultType: CameraResultType.Uri
})
// The result will vary on the value of the resultType option.
// CameraResultType.Uri - Get the result from image.webPath
// CameraResultType.Base64 - Get the result from image.base64String
// CameraResultType.DataUrl - Get the result from image.dataUrl
imageSrc.value = image.webPath
}
return {
essentialLinks: linksList,
leftDrawerOpen,
toggleLeftDrawer () {
leftDrawerOpen.value = !leftDrawerOpen.value
},
imageSrc,
captureImage,
}
}- Pour tester en mode application web : quasar dev
- Normalement, quand on clique sur le bouton, un widget apparaît pour prendre une photo, si l'ordinateur possède une caméra. Sinon, il propose d'aller chercher une photo sur le disque.
- Pour tester sur un simulateur de mobile android : quasar dev -m capacitor -T android